2019ICDE-Presto: SQL on Everything

本文发表于2019年,但是presto从2013年开始就有了,2019年原作者从Facebook分道扬镳。有关这段爱恨情仇可以在trino官网(presto主流继承版本)中看到。本文的作者是presto的原作者,发表于2019年,此时presto已经是比较成熟完善的系统了,学习的价值更大。
Abstract
Presto是分布式查询引擎,支持SQL负载。既能承担亚秒级别的交互式查询,也要能支持几小时的ETL任务。
主要特性是:灵活、自适应、扩展性强(支持多个外部源,包括HDFS、RDBMS、NoSQL、流处理系统)。
I. INTRODUCTION
Presto作为交互式的查询引擎,从2013年诞生开始,已经在Facebook以及世界上众多大公司使用,以满足端上用户交互式查询分析的需求。它主要有以下特性:
- 多租户系统。要支持几百个查询并行;要有扩展性,能扩展到几千个节点去。
- 集成性。管理员可以设置集群,让它可以兼容多个外部数据源,甚至在一条SQL里用多个数据源。
- 灵活性。能应对各种工作负载。
- 高度优化。多个query可以共享一个JVM运行,当然这就需要调度、资源管理、隔离等。
II. USE CASES
A. Interactive Analytics
对小批量数据(压缩后几百GB~3TB)进行交互式、探索式分析,只想要秒级别的返回,或者要一个初始的近似值(探索式分析)。
B. Batch ETL
ETL操作更注重吞吐量和资源利用效率,单查询的响应时间不太重要。
C. A/B Testing
不仅是日级别的A/B Test,要在若干小时内就提供结果。而且要可以有任意切片与切块,对时间和其它维度进行切分聚合,查询类型是固定的,但是查询难度较大,要有多次JOIN和聚合,时间要控制在(5s~30s)。
D. Developer/Advertiser Analytics
这里是讲Facebook提供一个开发平台给其它外部的开发者来用,开发者来分析自己应用数据时体量很大,但是选择度也很高,他只会访问自己app的数据。这个延迟要在(50ms~5s)。
III. ARCHITECTURE OVERVIEW
典型的主从式架构,一个coordinator,多个worker,协调者负责接收、语法解析、逻辑计划、优化等各个方面,唯一不负责的就是具体执行。
corrdinator将task分发给各个worker,然后遍历splits,将这个外部数据源的handler分发给对应的task,最终由worker thread事实上去从外部数据源取数据。每个worker都可能会并发的同时处理多个query,在具体执行时,会将计算任务尽可能的流水线化,所有的中间结果(包括shuffle),都在内存缓存。
presto利用plugins将内部数据类型和API做的非常丰富,又利用connectors可以和众多外部数据源交互(Connector API具体需要实现: Metadata API, Data Location API, Data Source API, and Data Sink API)。
IV. SYSTEM DESIGN
A. SQL Dialect
尽可能符合了ANSI SQL的规范。而且在此基础上对于复杂类型提供了更高层的语法(匿名函数、高级函数)。
B. Client Interfaces, Parsing, and Planning
coordinator给客户端暴露出来一组http接口,以及CLI命令,JDBC以提供访问。
语法解析是基于ANTLR(一个开源的语法解析器)生成一个抽象语法树,而且在这里还做了类型的判断以及作用域的判断;
基于这个抽象语法树,presto生成了一个纯逻辑IR(中间表示),以树形表示。
C. Query Optimization
优化器为逻辑IR生成一个物理执行计划,这个物理执行计划代表这个查询的最优执行过程。
presto内部有一系列规则,每个规则可能匹配一个逻辑IR的子树,那么就可以将这个子树替换为相应的模式。presto用贪婪地方式应用这些规则,直到到达某个阈值。
这里就到了一个查询优化器的领域里。一般是采用基于代价的计划评估,presto已经支持了两种基于代价的评估,将表和列的统计信息都纳入考虑,可以对join策略选择和join重新排序有帮助。
接下来说一些presto采用的优化规则:
- Data Layouts:presto可以基于数据的物理布局提供优(connector有Data Layout API)。presto可以根据数据的物理布局(位置、分区、聚合、索引、行列存储)进行最优的选择。
- Predicate Pushdown:当范围查询和等值查询下推可以提高筛选效率时,optimizer可以和connector协作决定。
这个谓词下推范围很广,比如水平分区的MySQL,presto就会将查询下推到每一个shard,令其返回满足条件的数据;presto会优先选择那些有索引的列进行下推,效率更高;对于批处理操作,可以利用分区的裁剪进行下推。 - Inter-node Parallelism:optimizer的一个工作就是定义stage。stage是能进行并行化的一些操作,并行化是指同样的操作,不同的数据,分配给不同的Worker去做。然而不同的stage之间要进行shuffle以交换数据,这个过程负载极高,需要谨慎考虑。
- Data Layout Properties:物理上的数据布局可以用来最优化shuffle的数量。尤其是在需要大的join情况,可以根据join列进行partition,利用co-located join策略进行资源优化。再比如,join列被索引的情况下,index nested loop join可以成为一种策略。
- Node Properties:物理计划树上的节点可以记录输出结果的属性(partition, sort, grouping statistics等),同时也可以表明当前节点required的,和preferred的属性,这些要求将在引入shuffle时候被考虑到。
在分区选择策略上,presto依然是贪婪地选择能满足更多Required属性的分区,这意味着一般来说presto选择的partition columns是很少的,这有可能导致数据偏斜。
- Intra-node Parallelism:这是说节点内的多线程并行,在一个stage内,可以有多个sections并行。节点内部的并行非常高效,信息状态的共享很容易。对于一些plan中的下游瓶颈(比如小查询的skew,ETL的下游聚合节点),节点内的并行非常奏效。
D. Scheduling
presto coordinator首先划分Stage,接着要在stage内部划分出平行的task。在每一个local task内部,又可以通过流水线的方式来提高吞吐量。流水线就是一系列定义明确的计算操作,optimizer还可以根据策略将pipiline进一步分割,达成更高的并行性。operator之间的数据交换,通过一个local in-memory data shuffle。
谈到调度,presto有两种调度,第一种是stage划分,第二种是stage内部task划分以及分配。
- Stage Scheduling:
- all-at-once policy:数据一旦可用,就立即执行,并发执行所有可以执行的stage,这对于时延需求型应用是合适的;
- phased policy:通过一个有向数据流图,识别一些强相连的组件,以拓扑顺序去执行,避免死锁。对于资源的利用是更高效的,这对于吞吐量需求型应用是合适的。
- Task Scheduling:一旦stage划分好了,就对stage内部的task进行调度规划。Stage分为两类,从External source读取数据的leaf stage和从前一个stage读取数据的intermediate stage。
- Leaf Stage:对于leaf stage task scheduler来说,网络和connector(数据源)的限制,通常会被纳入主要考虑。scheduler主要就是用connector Data Layout API来决定task放置的。
Profiling显示:大部分的CPU cost(leaf stage)都来自于数据的解压缩、解码、转换、筛选过滤,这些操作并行度极高,这就意味着如果没有network和connector,并行度可以完全取决于物理机器节点的个数。对于云存储的环境里,同样是成立的。但是本地存储的环境下,可能还要考虑数据的Locality。对于Facebook这样的云存储环境,网络拓扑结构也是task分配的一个考量,一般会分配同机架的数据。 - Intermediate Stage:中间stage可以在任意一个节点中进行,然而仍然要决定有多少个tasks。这个数量取决于connector,plan,要求的数据布局,以及部署等。presto还可以在任务执行过程中动态地决定task数量。
- Leaf Stage:对于leaf stage task scheduler来说,网络和connector(数据源)的限制,通常会被纳入主要考虑。scheduler主要就是用connector Data Layout API来决定task放置的。
- Split Scheduling:split是针对于数据存储来说的,一个split就是数据的一部分,一个handler/iterator。corrdinator要求Connector去遍历所有批次的splits,然后惰性的为worker分配splits。每一个worker都有一个splits队列,分配时向队列最短的worker进行分配。这样做有几点好处:
- 时间上:没有必要读取所有的splits,然后再进行计算操作,可以以流水线的方式进行执行,极大的加快了速度。对于一些where和limit操作,很可能执行一半就cancel掉就可以了。
- 空间上:没有必要在内存保存所有splits的metadata,避免coordinator内存溢出。
E. Query Execution
1. Local Data Flow:
一个split在一个worker内部,通过一个Driver loop来执行。split在Driver内部分成若干个page,每个page是driver loop操作的一个基本单元,按照列进行编码,通常是1列多行,有固定的结构。
driver loop非常复杂,适合于多任务的协作,即使没有新数据输入,每次循环迭代也可以让数据move到下一个operator。
2. Shuffles
presto把shuffle data全部缓存到内存buffer里,shuffle过程通过长轮询http来完成。server一直保留数据,直到Client来申请下一批数据而且带着上一批数据的token时候(ACK+next request)才会删掉。
presto并行度的调整,主要基于buffer的利用率。output buffer太满有效内存就少了,拖慢执行;input buffer太空处理效率不高。
因此presto监控buffer使用率。使用率太高的时候就要削弱并行度,减缓处理速度,这对于一个很慢的client的实时查询来说比较重要,可以提高资源利用率和并发量。
对于接收端,监控每一个http请求每一批的数据move的量,以此来调整给每个http请求的并行度,保证input buffer一直在写入,但不会写满,这有可能会让上游worker速度放缓。
3. Writes
写方面,尤其是ETL操作需要大量的写,此时presto也将并行利用起来,不过问题在于,如果过度并行,将导致产生过多小文件;如果不并行,写又太慢了。因此presto需要一个自适应的并行度,方法同样是监测output buffer的水位,水位太高就要增加一些并行度,添加新的worker node。
F. Resource Management
presto实现的是一个集成的,细粒度的资源管理系统,用来最大化资源利用率。
1. CPU Scheduling
Presto主要的优化目标是集群整体的吞吐量(即总体的CPU利用率)。但是在节点层面,会额外去为一些小查询考虑周转时间尽可能小,以及CPU代价相似的查询的公平调度(用于保证交互式查询场景)。
一个task的资源使用被定义成task中所有Splits的CPU时间的总和。为了避免更多的协调开销,Presto就在本地对各个task进行调度,跟踪task的资源使用。
调度时有一个quanta的概念:每个split被规定一次在一个线程上执行的最长时间,quanta不会超过1s,一般是对1s进行等分。执行一旦超过quanta,split必须放弃线程,重新回归队列排队。
有的时候执行不到一个quanta,也会被强制踢下线程,比如:output buffer满了/input buffer空了/系统内存满载。
切换时,线程从splits队列中挑选一个split进行执行。这个调度方案采用的是多级反馈队列。这个队列是以task为级别进行归类的,一个task可能包含若干个splits待执行。如果task已经执行了很长的总时长了,就会在更高级别的队列中,每个队列都会分到一个固定比例的CPU时长,更高级的队列分配的时长比例会更小。
presto会利用一个低成本的yield指令处理任务切换,甚至在一个operator内部都可以被停止掉。即使如果有某些operator执行超过quanta无法停止,那么presto也会对该任务进行“收费”,让他以后执行的概率更小以进行补偿。
以上的策略(quanta+multi-level feedback queues),可以看到presto对小查询有preference,同时也能兼容大任务。这种频繁的调度切换,使得调度水平更接近optimal,总的排队时间减少了。
2. Memory Management
内存池:
Presto的内存使用主要分为两类:用户内存和系统内存。
用户内存主要是执行查询时所需要的内存,一般和数据输入规模成比例;
系统内存主要是执行过程时的一个“副产品” ,比如shuffle buffer这种,和输入无关。
presto对用户内存和总内存使用都有限制(包括单节点使用和总使用量),超过限制的查询会被kill掉。而有一些skew query会导致单节点压力过大,很多个skew queries在极端情况下会让一个节点压力巨大,而其他节点却很轻松。Presto为了解决偏斜的问题,提出了一下两种机制,这使得用户一般都可以过度提交任务,而系统不会崩溃。
Spilling(溢出):
溢出很容易理解,当一个节点内存满了,就把它上面的task的状态刷到磁盘里,直到腾出了足够大的内存执行任务就可以了。task被溢出的顺序是按照已经执行的时间来递增的。
Presto提供了为聚合和hash join溢出的支持,但实际上,facebook部署使用的时候根本就没用溢出,一来Facebook内存足够大,二来云存储部署的话根本也没有本地磁盘,存到云盘开销太大了。
Reserved Pool(保留池):
保留池的概念有点类似spark的off-heap memory。在所有节点上,除了我们刚才说到的两种常规内存,还有一种保留内存。保留内存在整个集群上统一分配使用,同时只能跑一个query(避免死锁)。如果某个节点常规内存用尽了,就把该节点内存占用最大的task移动到集群的保留内存中去执行。此时如果还有节点想要使用保留内存,只能等候保留内存中的任务完成,自己节点上的task全部被阻塞。
这种方法也是比较浪费的,因为可能保留内存的大小在每个节点上也未必是固定的。
G. Fault Tolerance
总的来说,presto基本没有容错和高可用,low-level的错误普遍通过重试来解决。
对于集群的高可用,要么是coordinator热备,要么是有多个集群,对于worker可以由监控系统进行监控。presto不愿意用诸如checkpoint, replication之类的重的高可用机制牺牲性能。
worker启动/重启后,主动向coordinator联系加入,待coordinator确认,Worker就加入到及群众了,非常简单。
V. QUERY PROCESSING OPTIMIZATIONS
A. Working with the JVM
Presto是用Java实现的,还是要依赖JVM执行。一些关键影响性能的代码,比如压缩/解压缩,checksum算法还是尽可能的精细化实现。虽然不知道JIT(Just-In-Time) Compiler具体怎么进行代码生成,但是也可以手动进行一些编译技术(内联函数、嵌入CPU指令、循环展开)强制优化。也考虑用Graal这种新型的VM。
GC机制也非常影响性能,Presto选择的是G1GC,同时对大对象、链接图对象进行限制和扁平化处理以提升性能。
B. Code Generation
- 表达式计算:Presto为各种复杂的表达式生成了bytecode高效处理表达式。
- JIT启发式优化:代码生成器可以基于presto查询引擎对于查询计算语义的理解做出更合适的JIT优化。优化主要有以下几个目标:
- 由于基于quanta的频繁上下文切换,一些tight的循环展开可能会被破坏;
- 很多计算的类型是可以预知的,有利于内联虚方法;
- JIT会为每个task生成一个bytecode,而且会根据task具体的数据对bytecode进行优化,进一步,JIT还会随着数据的变化对bytecode进行进一步的调整。
总的来说,Bytecode的生成加速了计算。无论是inline,还是循环展开、自动向量化等编译技术,最终都体现在高效的CPU利用和更少的cache miss上,结果都是细粒度的加速了计算。
C. File Format Features
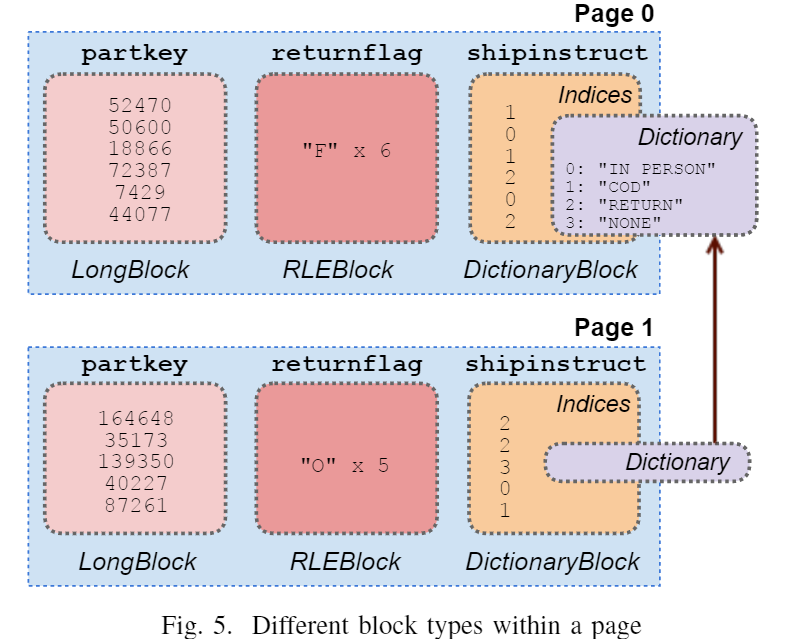
Connctor为Presto传输数据时的单位是Page,每个Page包含若干个block,block是按照内存结构进行扁平化处理的单个列。不同的block有不同的功能,不同的page还可能share同一个block。
Presto还可能对特定的Connctors的文件格式直接提供服务,比如ORC文件,可以利用其中的文件元信息做一些skip_data的优化,readers还可以直接将压缩文件转换成内存block,使得非常高效。
D. Lazy Data Loading
Presto提供一些lazy block,直到真正程序去读取这些block的数据时,才会去真正的取数据,这一功能对于一些筛选性较强的任务有非常大的CPU提升,因为CPU通常都忙于解压缩、解码之类的事情。
E. Operating on Compressed Data
Presto有很多直接在压缩数据上的操作(即在RLE blocks和字典blocks上)。在很多操作中,会尽量有字典block代替数据本身的访问。
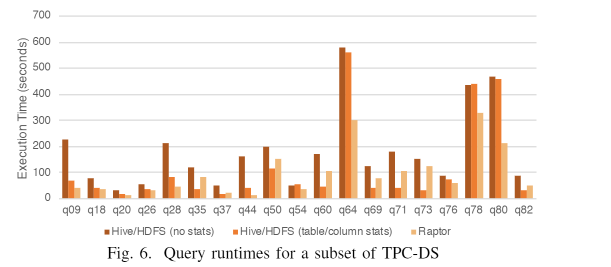
VI. PERFORMANCE
实验环境:Presto v0.211,TPC-DS 30TB(只选择了低内存占用的query,需要溢出的没选),100节点,每节点28核,256GB内存,1.6TB SSD。对比了几种connector:Hive/HDFS(没有统计信息和有统计信息,共享存储),Raptor(类似于Hive,但是是本地存储的)。文件格式都是ORC。