什么是列式存储
在传统的行式数据库系统中,数据按如下顺序存储:
| Row | WatchID | JavaEnable | Title | GoodEvent | EventTime |
|---|---|---|---|---|---|
| #0 | 89354350662 | 1 | Investor Relations | 1 | 2016-05-18 05:19:20 |
| #1 | 90329509958 | 0 | Contact us | 1 | 2016-05-18 08:10:20 |
| #2 | 89953706054 | 1 | Mission | 1 | 2016-05-18 07:38:00 |
| #N | … | … | … | … | … |
处于同一行中的数据总是被物理的存储在一起。
常见的行式数据库系统有:MySQL、Postgres和MS SQL Server。
在列式数据库系统中,数据按如下的顺序存储:
| Row: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| WatchID: | 89354350662 | 90329509958 | 89953706054 | … |
| JavaEnable: | 1 | 0 | 1 | … |
| Title: | Investor Relations | Contact us | Mission | … |
| GoodEvent: | 1 | 1 | 1 | … |
| EventTime: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
这些示例只显示了数据的排列顺序。来自不同列的值被单独存储,来自同一列的数据被存储在一起。
常见的列式数据库有:clickhouse、doris、starrocks、druid、 Vertica、 Paraccel (Actian Matrix,Amazon Redshift)、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 MonetDB (VectorWise, Actian Vector)、 LucidDB、 SAP HANA、 Google Dremel、 Google PowerDrill、 Druid、 kdb+。
不同的数据存储方式适用不同的业务场景,数据访问的场景包括:进行了何种查询、多久查询一次以及各类查询的比例;每种类型的查询(行、列和字节)读取多少数据;读取数据和更新之间的关系;使用的数据集大小以及如何使用本地的数据集;是否使用事务,以及它们是如何进行隔离的;数据的复制机制与数据的完整性要求;每种类型的查询要求的延迟与吞吐量等等。
ORC 列存数据结构
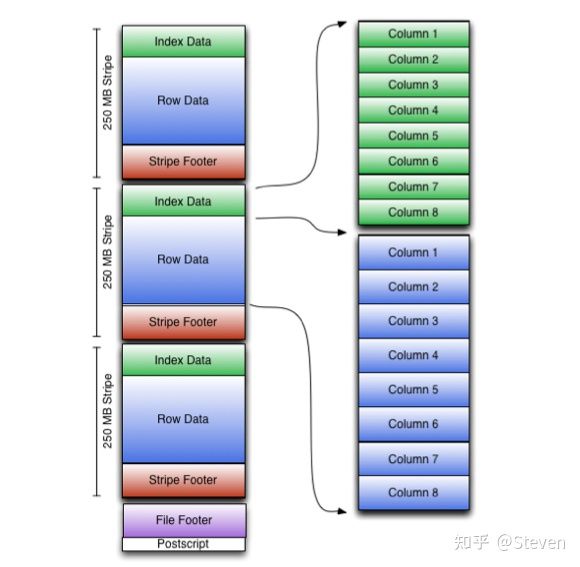
Index data(索引数据): 包括每列的最小值和最大值以及行在每列中的位置。ORC 索引仅用于stripe和行组的选择,而不用于回答查询。
Row data(行数据):用于表扫描。
stripe footer(页脚):包含流位置的目录。它还包含列级聚合计数、最小值、最大值和总和。
File footer(文件页脚):
- 文件中的stripe列表。
- 每个stripe的行数。
- 每列的数据类型。
Postscript:附有压缩参数和压缩页脚的大小,在文件的末尾。
ORC 与 Parquet
- Parquet更能存储嵌套数据。
- ORC 更有能力进行谓词下推。
- ORC 支持 ACID 属性。
- ORC 的压缩效率更高。
Clickhouse数据存储结构
lickhouse中有众多表引擎,不同的表引擎在底层数据存储上千差万别,在功能和性能上各有侧重。但实际生产中,使用最广泛的表引擎就是MergeTree系列。
MergeTree家族是Clickhouse中最有特色,也是功能最强大的表引擎,实现了数据的partitioning、replication、mutation、merge,以及在merge基础上的replace、aggregation。为了了解这些功能是如何实现的,首先需要知道在MergeTree引擎时,数据文件的组织、存储形式及内容。
1 | clickhouse |
20210224_0_1_1_2 这些目录命名的规则:
1 | PartitionId_MinBlockNum_MaxBlockNum_Level_{data_version} |
PartitionId,分区Id。其值是由创建表时所指定的分区键决定的,由于我们创建表时使用的分区键为toYYYYMM(Birthday),即生日的年月,而插入的Birthday为2000-02-01,所以其值为200002。
MinBlockNum、MaxBlockNum,最小最大数据块编号。其值在单张表内从1开始累加,每当新创建一个分区目录其值就会加1,且新创建的分区目录MinBlockNum和MaxBlockNum相等,只有当分区目录发生合并时其值才会不等。由于这是该表第一次插入数据,所以MinBlockNum和MaxBlockNum都为1。
Level,分区被合并的次数。level和MinBlockNum以及MaxBlockNum不同,它不是单张表内累加的,而是单张表中的单个分区内累加的。每当新创建一个分区目录其值均为0,只有当分区目录发生合并时其值才会大于0。
data_version表示mutate操作的data_version,每一次mutate都会生成一个新的data_version的part目录,这个值的含义其实和block_number类似,同时也和block_number共用自增id空间,通过这个值可以判断每个part是否包含在本次mutate操作的影响范围内
文件介绍
在 20210224_0_1_1_2 目录下结构
1 | ├── 200002_1_1_0 |
| 文件名 | 描述 | 作用 |
|---|---|---|
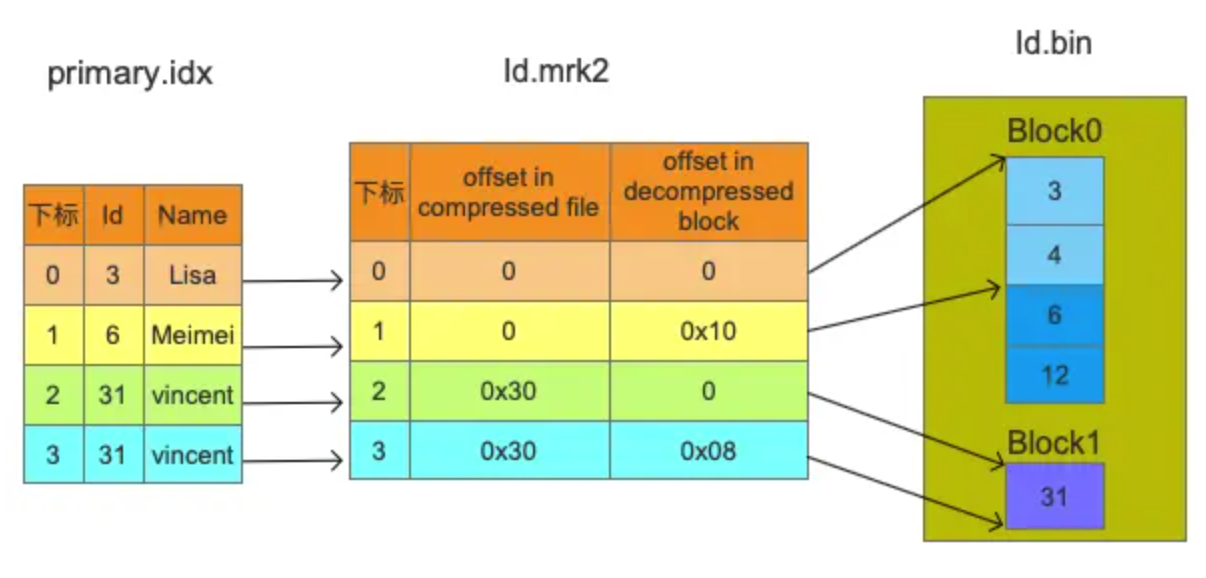
| primary.idx | 索引文件 | 用于存放稀疏索引 |
| [Column].mrk2 | 标记文件 | 保存了bin文件中数据的偏移信息,用于建立primary.idx和[Column].bin文件之间的映射 |
| [Column].bin | 数据文件 | 存储数据,默认使用lz4压缩存储 |
| partition.dat | 分区文件 | 用于保存分区表达式生成的值 |
| minmax_[Column].idx | minmax索引 | 用于记录当前分区下分区字段的最小最大值 |
| columns.txt | 列信息文件 | 用于保存表的列字段信息 |
| count.txt | 计数文件 | 用于记录当前分区目录下数据的总行数 |
| checksums.txt | 校验文件 | 存放以上各个文件的size以及哈希值,用于快速校验文件的完整性 |
index

bin
每一列均有一个单独的列存文件{column_name}.bin来存储实际的数据。为了尽可能减小数据文件大小,文件需要进行压缩,默认算法由part目录下的default_compression_codec文件确定。
如果直接将整个文件压缩,则查询时必须读取整个文件进行解压,显然如果需要查询的数据集比较小,这样做的开销就会显得特别大,因此一个列存文件是一个个小的压缩数据块组成的。一个压缩数据块中可以包含若干个granule的数据,而granule就是Clickhouse中最小的查询数据集,后面的索引以及标记也都是围绕granule来实现的。granule的大小由配置项index_granularity确定,默认8192;压缩数据块大小范围由配置max_compress_block_size和min_compress_block_size共同决定。每个压缩块中的header部分会存下这个压缩块的压缩前大小和压缩后大小。整个结构如下图所示:
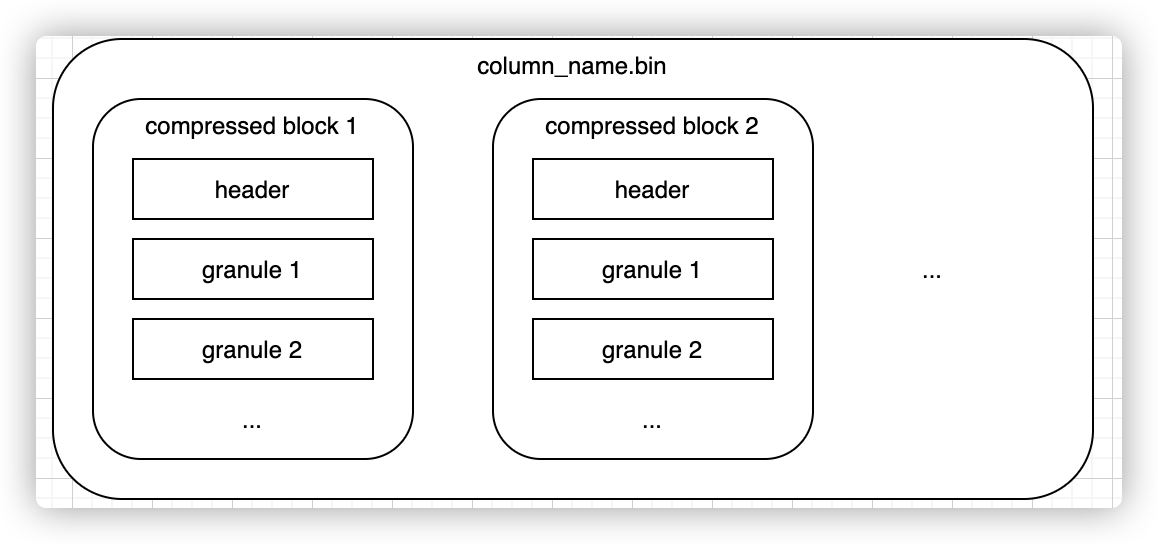
bin文件由若干个Block组成,由上图可知Id.bin文件中包含两个Block。每个Block主要由头部的Checksum以及若干个Granule组成,Block的格式如下图所示:
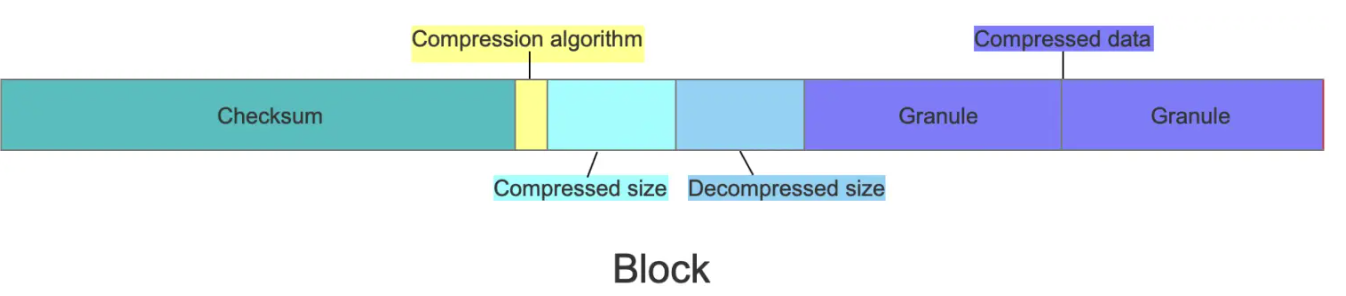
- Checksum,16 Bytes,用于对后面的数据进行校验。
- Compression algorithm,1 Byte,默认是LZ4,编号为0x82。
- Compressed size,4 Bytes,其值等于Compression algorithm + Compressed size + Decompressed size + Compressed data的长度
- Decompressed size,4 Bytes,数据解压缩后的长度。
- Compressed data,压缩数据,长度为Compressed size - 9。
MARK
通过primary.idx中的索引寻找mrk2文件中对应的Mark非常简单,如果要寻找第n(从0开始)个index,则对应的Mark在mrk2文件中的偏移为n*24,从这个偏移处开始读取24 Bytes即可得到相应的Mark。

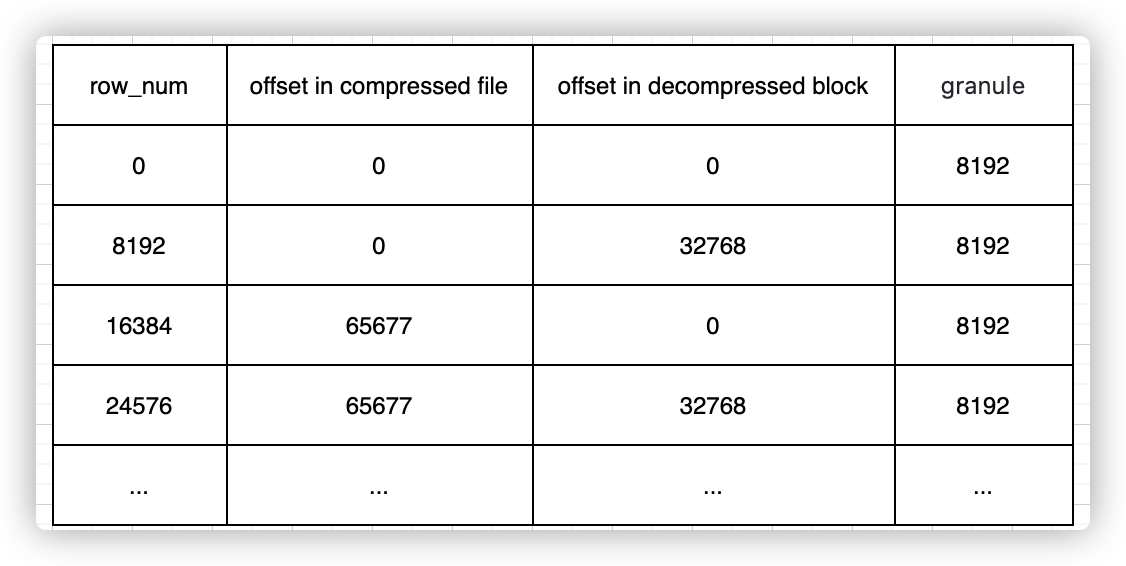
索引到数据