
JVM调优参数的设置实例
其一是标准参数(-),所有的JVM实现都必须实现这些参数的功能,而且向后兼容;
其二是非标准参数(-X),默认jvm实现这些参数的功能,但是并不保证所有jvm实现都满足,且不保证向后兼容;
其三是非Stable参数(-XX),此类参数各个jvm实现会有所不同,将来可能会随时取消,需要慎重使用;
1 | -XX:+<option> 启用option,例如:-XX:+PrintGCDetails启动打印GC信息的选项,其中+号表示true,开启的意思 |
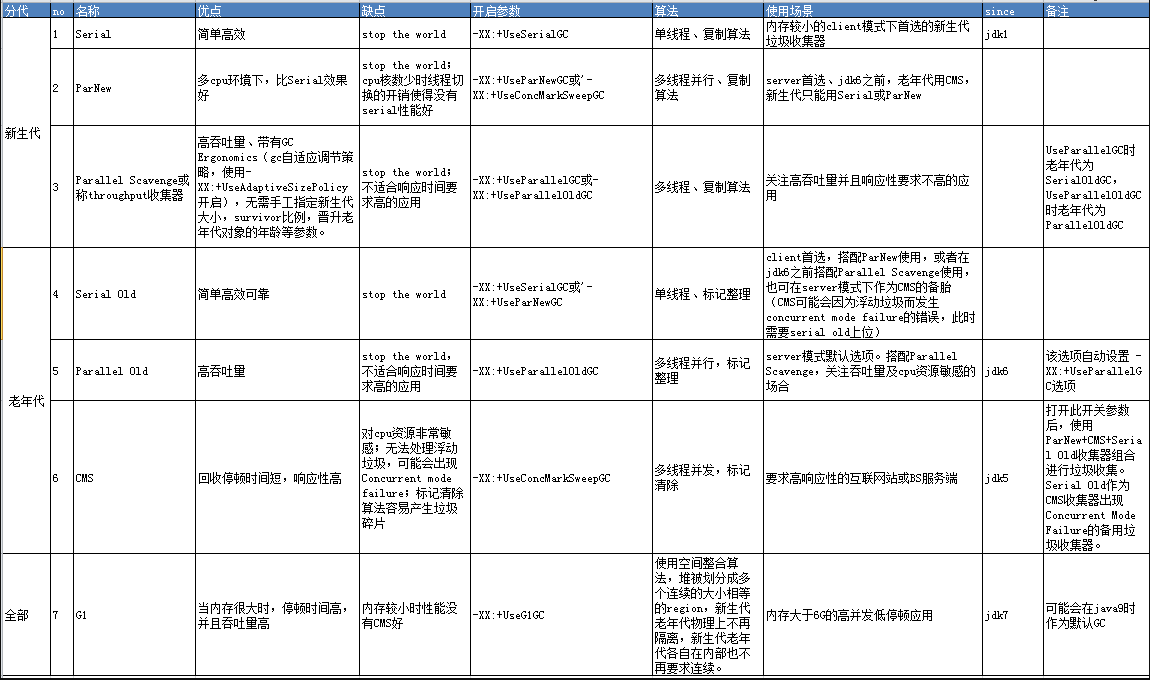
GC 类型
java的gc回收的类型主要有几种 UseSerialGC,UseConcMarkSweepGC,UseParNewGC,UseParallelGC,UseParallelOldGC,UseG1GC
SerialGC(-XX:+UseSerialGC)
使用串行回收器进行回收,这个参数会使新生代和老年代都使用串行回收器,新生代使用复制算法,老年代使用标记-整理算法。Serial收集器是最基本、历史最悠久的收集器,它是一个单线程收集器。一旦回收器开始运行时,整个系统都要停止。
Client模式下默认开启,其他模式默认关闭。
-XX:+UseParNewGC
Parallel是并行的意思,ParNew收集器是Serial收集器的多线程版本,使用这个参数后会在新生代进行并行回收,老年代仍旧使用串行回收。新生代S区任然使用复制算法。操作系统是多核CPU上效果明显,单核CPU建议使用串行回收器。打印GC详情时ParNew标识着使用了ParNewGC回收器。
默认关闭。
ParallelGC(-XX:+UseParallelGC)
代表新生代使用Parallel收集器,老年代使用串行收集器。Parallel Scavenge收集器在各个方面都很类似ParNew收集器,它的目的是达到一个可以控制的吞吐量。吞吐量为CPU用于运行用户代码的时间与CPU总消耗时间的比值,即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间),虚拟机运行100分钟,垃圾收集花费1分钟,那吞吐量就99%。
Server模式默认开启,其他模式默认关闭。
Parallel Scavenge提供了两个参数用于控制吞吐量
-XX:MaxGCPauseMillis参数用于设置最大停顿时间,它的参数运行值是一个大于0的毫秒数,收集器将尽力保证垃圾回收时间不超过设定值,系统运行的需要回收的垃圾总量是固定的,缩短停顿时间的同时会增大回收频度。
-XX:GCTimeRatio参数用户控制垃圾回收时间占比,它运行的参数值是0-100的整数,如果参数设置为19,代表最大GC时间占总时间的5%(1/(1+19))。
Parallel收集器还提供了自适应的调节策略-XX:UseAdaptiveSizePolicy,即JVM会根据实际运行情况动态调整新生代大小、新生代和s区比例、晋升老年代对象大小等细节参数。
-XX:+UseParallelOldGC
新生代和老年代都使用并行收集器。打印出的GC会带PSYoungGen、ParOldGen关键字。
1
[Full GC [PSYoungGen: 4032K->0K(145920K)] [ParOldGen: 164500K->138362K(246272K)] 168532K->138362K(392192K) [PSPermGen: 67896K->67879K(136192K)], 1.006
CMS (-XX:+UseConcMarkSweepGC)
Concurrent Mark Sweep 并发标记清除,即使用CMS收集器。它是和应用程序线程一起执行,相对于Stop The World来说虚拟机停顿时间较少。停顿减少,吞吐量会降低。
它使用的是 标记清除算法,运作过程为四个步骤,分别是 初始标记—并发标识—重新标记—并发清除。(细节见:https://blog.csdn.net/zy1994hyq/article/details/102495305)
它是老年代的收集算法,新生代使用ParNew收集算法。
默认关闭
CMS收集器的缺点是对服务器CPU资源较为敏感,在并发标记时会降低吞吐量。它使用的标记清除算法也会产生大量空间碎片,空间碎片的存在会加大Full GC的频率,虽然老年代还有足够的内存,但是因为内存空间连续,不得不进行Full GC。
搭配参数:
-XX:+ UseCMSCompactAtFullCollection : Full GC后,进行一次整理,整理过程是独占的,会引起停顿时间变长。仅在使用CMS收集器时生效。
-XX:ParallelCMSThreads,设置并行GC时进行内存回收的线程数量
JVM设置参考:
参考:https://cloud.tencent.com/developer/article/1198494
1 | -server ## 服务器模式 |
Xms与Xmx配置相同的值,为了能够在GC后不需要重新分隔计算堆区的大小而浪费资源。
其他暂时没用到的:
1 | NewRatio:3 ## 新生代与年老代的比例。比如为3,则新生代占堆的1/4,年老代占3/4。 |
CMS
部分重要参数
- -XX:+UseConcMarkSweepGC:激活CMS收集器,默认情况下使用ParNew + CMS + Serial Old的收集器组合进行内存回收,Serial Old作为CMS出现“Concurrent Mode Failure”失败后的后备收集器使用。
- -XX:CMSInitiatingOccupancyFraction={x}:触发CMS收集器的内存比例。比如60%的意思就是说,当内存达到60%,就会开始进行CMS并发收集。
- -XX:CMSFullGCsBeforeCompaction={x}:在进行了{x}次CMS算法之后,对老年代进行一次compaction内存整理
- -XX:UseCMSCompactAtFullCollection:这个前面已经提过,用于在每一次CMS收集器清理垃圾后送一次内存整理
- -XX:+CMSPermGenSweepingEnabled & -XX:+CMSClassUnloadingEnabled:让CMS默认遍历永久代(Perm区)
- -XX:ParallelCMSThreads={x}:设置CMS算法中并行线程的数量为{x}。(默认启动(CPU数量+3) / 4个线程。)
- -XX:+ExplicitGCInvokesConcurrent:用户程序中可能出现利用System.gc()触发系统Full GC(将会stop-the-world),利用这个参数可以指定System.gc()直接调用CMS算法做GC。
- -XX:+DisableExplicitGC:该参数直接让JVM忽略用户程序中的System.gc()
CMS 基础知识
参考:https://segmentfault.com/a/1190000005174819
在CMS整个过程中有两个步骤是STW的,如图红色部分

CMS并非没有暂停,而是用两次短暂停来替代串行标记整理算法的长暂停,它的收集周期是这样:
- 初始标记(CMS-initial-mark),从root对象开始标记存活的对象
- 并发标记(CMS-concurrent-mark)
- 重新标记(CMS-remark),暂停所有应用程序线程,重新标记并发标记阶段遗漏的对象(在并发标记阶段结束后对象状态的更新导致)
- 并发清除(CMS-concurrent-sweep)
- 并发重设状态等待下次CMS的触发(CMS-concurrent-reset)。
2、FULL GC阶段之前先在进行一次年轻代的GC的意义是:Yong区对象引用了Old区的对象,如果在Old区进行清理之前不进行Yong区清理,就会导致Old区被yong区引用的对象无法释放。设置如下:
1 | -XX:+ScavengeBeforeFullGC |
CMS GC 日志输出解读
在CMS GC 时,使用参数-XX:+PrintGCDetails 和 -XX:+PrintGCTimeStamps 会输出很多日志信息,了解这些信息可以帮我们更好的调整参数,以获得更高的性能。
我们来看下在JDK1.4.2_10 中CMS GC日志示例:
了解 CMS 垃圾回收日志
原文oracle博客(目前找不到了) https://blogs.oracle.com/poonam/entry/understanding_cms_gc_logs
参考http://ifeve.com/jvm-cms-log/
CMS正常运行周期打印的日志
39.910: [GC 39.910: [ParNew: 261760K->0K(261952K), 0.2314667 secs] 262017K->26386K(1048384K), 0.2318679 secs]
新生代使用 (ParNew 并行)回收器。新生代容量为261952K,GC回收后占用从261760K降到0,耗时0.2314667秒。(译注:262017K->26386K(1048384K), 0.2318679 secs 表示整个堆占用从262017K 降至26386K,费时0.2318679)
40.146: [GC [1 CMS-initial-mark: 26386K(786432K)] 26404K(1048384K), 0.0074495 secs]
开始使用CMS回收器进行老年代回收。初始标记(CMS-initial-mark)阶段,这个阶段标记由根可以直接到达的对象,标记期间整个应用线程会暂停。
老年代容量为786432K,CMS 回收器在空间占用达到 26386K 时被触发
40.154: [CMS-concurrent-mark-start]
开始并发标记(concurrent-mark-start) 阶段,在第一个阶段被暂停的线程重新开始运行,由前阶段标记过的对象出发,所有可到达的对象都在本阶段中标记。
40.683: [CMS-concurrent-mark: 0.521/0.529 secs]
并发标记阶段结束,占用 0.521秒CPU时间, 0.529秒墙钟时间(也包含线程让出CPU给其他线程执行的时间)
40.683: [CMS-concurrent-preclean-start]
开始预清理阶段
预清理也是一个并发执行的阶段。在本阶段,会查找前一阶段执行过程中,从新生代晋升或新分配或被更新的对象。通过并发地重新扫描这些对象,预清理阶段可以减少下一个stop-the-world 重新标记阶段的工作量。
40.701: [CMS-concurrent-preclean: 0.017/0.018 secs]
预清理阶段费时 0.017秒CPU时间,0.018秒墙钟时间。
40.704: [GC40.704: [Rescan (parallel) , 0.1790103 secs]40.883: [weak refs processing, 0.0100966 secs] [1 CMS-remark: 26386K(786432K)] 52644K(1048384K), 0.1897792 secs]
Stop-the-world 阶段,从根及被其引用对象开始,重新扫描 CMS 堆中残留的更新过的对象。这里重新扫描费时0.1790103秒,处理弱引用对象费时0.0100966秒,本阶段费时0.1897792 秒。
40.894: [CMS-concurrent-sweep-start]
开始并发清理阶段,在清理阶段,应用线程还在运行。
41.020: [CMS-concurrent-sweep: 0.126/0.126 secs]
并发清理阶段费时0.126秒
41.020: [CMS-concurrent-reset-start]
开始并发重置
41.147: [CMS-concurrent-reset: 0.127/0.127 secs]
在本阶段,重新初始化CMS内部数据结构,以备下一轮 GC 使用。本阶段费时0.127秒
这是CMS正常运行周期打印的日志,现在让我们一起看一下其他的CMS日志记录:
其他的CMS日志记
197.976: [GC 197.976: [ParNew: 260872K->260872K(261952K), 0.0000688 secs]197.976: [CMS197.981: [CMS-concurrent-sweep: 0.516/0.531 secs]
(concurrent mode failure): 402978K->248977K(786432K), 2.3728734 secs] 663850K->248977K(1048384K), 2.3733725 secs]
这段信息显示ParNew 收集器被请求进行新生代的回收,但收集器并没有尝试回收,因为 它 预计在最糟糕的情况下, CMS 老年代中没有足够的空间容纳新生代的幸存对象。我们把这个失败称之为”完全晋升担保失败”。
因为这样,并发模式的 CMS 被中断同并且在 197.981秒时,Full GC被启动。这次Full GC,采用标记-清除-整理算法,会发生stop-the-world,费时2.3733725秒。CMS 老年代占用从 402978K 降到248977K。
避免并发模式失败, 通过增加老年代空间大小或者设置参数 CMSInitiatingOccupancyFraction 同时设置UseCMSInitiatingOccupancyOnly为true。参数 CMSInitiatingOccupancyFraction 的值必须谨慎选择,设置过低会造成频繁发生 CMS 回收。
有时我们发现,当日志中出现晋升失败时,老年代还有足够的空间。这是因为”碎片”,老年代中的可用空间并不连续,而从新生代晋升上来的对象,需要一块连续的可用空间。CMS 收集器是一种非压缩收集器,在某种类型的应用中会发生碎片。下面博客中 Jon 详细讨论了如何处理碎片问题:https://blogs.oracle.com/jonthecollector/entry/when_the_sum_of_the
从JDK 1.5 开始,CMS 收集器中的晋升担保检查策略有些变化。原来的策略是考虑最坏情况,即新生代所有对象都晋升到老年代 , 新的晋升担保检查策略基于最近晋升历史情况,这种预计晋升对象比最坏情况下晋升对象要少很多,因此需要的空间也会少点。如果晋升失败,新生代处于一致状态。触发一次 stop-the-world 的标记-压缩收集. 如果想在 UseSerialGC 中获得这种功能,需要设置参数 -XX:+HandlePromotionFailure.
283.736: [Full GC 283.736: [ParNew: 261599K->261599K(261952K), 0.0000615 secs] 826554K->826554K(1048384K), 0.0003259 secs]
GC locker: Trying a full collection because scavenge failed
283.736: [Full GC 283.736: [ParNew: 261599K->261599K(261952K), 0.0000288 secs]
当一个JNI 关键区被释放时会发生 Stop-the-world GC。新生代因为晋升担保失败回收失败,触发一次 Full GC.
CMS 可以运行在增量模式下(i-cms), 使用参数 -XX:+CMSIncrementalMode. 在增量模式下,CMS 收集器在并发阶段,不会独占整个周期,而会周期性的暂停,唤醒应用线程。收集器把并发阶段工作,划分为片段,安排在次级(minor) 回收之间运行。这对需要低延迟,运行在少量CPU服务器上的应用很有用。
以下是增量模式 CMS的日志.
2803.125: [GC 2803.125: [ParNew: 408832K->0K(409216K), 0.5371950 secs] 611130K->206985K(1048192K) icms_dc=4 , 0.5373720 secs]
2824.209: [GC 2824.209: [ParNew: 408832K->0K(409216K), 0.6755540 secs] 615806K->211897K(1048192K) icms_dc=4 , 0.6757740 secs]
新生代花费 537 毫秒 和 675 毫秒. 在2次收集之间 iCMS 短暂运行期间由icms_dc 表示,icms_dc 表示运行的占空比。这里占空比为4% .
简单计算下, iCMS 增量阶段费时 4/100 * (2824.209 – 2803.125 – 0.537) = 821 毫秒, 即 2次 GC 间隔时间的 4%
在JDK 1.5 中, CMS 增加一个并发可中止预清理(concurrent abortable preclean)阶段. 可中止预清理阶段,运行在并行预清理和重新标记之间,直到获得所期望的eden空间占用率。增加这个阶段是为了避免在重新标记阶段后紧跟着发生一次垃圾清除。为了尽可能区分开垃圾清除和重新标记 ,我们尽量安排在两次垃圾清除之间运行重新标记阶段。
可以通过JVM参数CMSScheduleRemarkEdenSizeThreshold 和 CMSScheduleRemarkEdenPenetration 控制 重新标记阶段。默认值是2m和50%. CMSScheduleRemarkEdenSizeThreshold 设置Eden区大小,低于此值时不启动重新标记阶段,因为回报预期为微不足道 CMSScheduleRemarkEdenPenetration 设置启动重新标记阶段时Eden区的空间占用率。(译注:根据下面描述 Eden 应该是指整个新生代)
预清理阶段后,如果Eden 空间占用大于 CMSScheduleRemarkEdenSizeThreshold 设置的值, 会启动可中止预清理,直到占用率达到 CMSScheduleRemarkEdenPenetration 设置的值, 否则,我们立即安排重新标记阶段.(译注:与上面说的正好相反,不知是不是我翻译有误)
7688.150: [CMS-concurrent-preclean-start]
7688.186: [CMS-concurrent-preclean: 0.034/0.035 secs]
7688.186: [CMS-concurrent-abortable-preclean-start]
7688.465: [GC 7688.465: [ParNew: 1040940K->1464K(1044544K), 0.0165840 secs] 1343593K->304365K(2093120K), 0.0167509 secs]
7690.093: [CMS-concurrent-abortable-preclean: 1.012/1.907 secs]
7690.095: [GC[YG occupancy: 522484 K (1044544 K)]7690.095: [Rescan (parallel) , 0.3665541 secs]7690.462: [weak refs processing, 0.0003850 secs] [1 CMS-remark: 302901K(1048576K)] 825385K(2093120K), 0.3670690 secs]
上面日志中,在预清理之后, 启动可中止预清理, 之后发生年轻代垃圾回收,年轻代占用从 1040940K 下降到 1464K. 当年轻代占用率达到 522484K 即堆的50%时,发生重新标记
注意在JDK1.5中,年轻代的垃圾回收日志输出在后面的重新标记阶段