
Presto查询计划
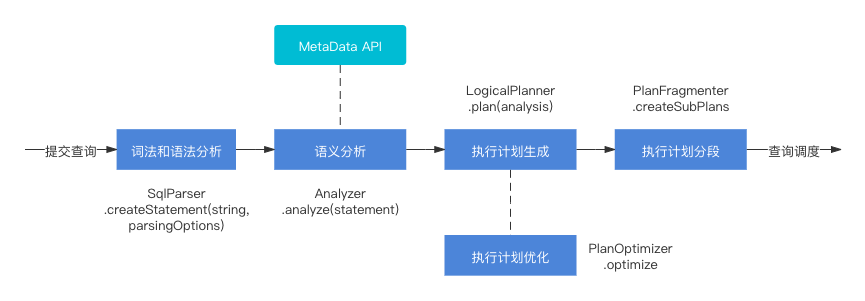
生成查询计划
生成查询计划 分为 语法分析、词法分析、语义分析、执行计划生成、执行计划优化、执行计划分阶段执行。
基本概念
Node
经过词法和语法分析后,会生成抽象语法树(AST),该语法树中的每一个节点都是Node(SQL语句的一部分,例如select部分,where部分),Node是一个抽象类,其实现类如下图,特别庞大:
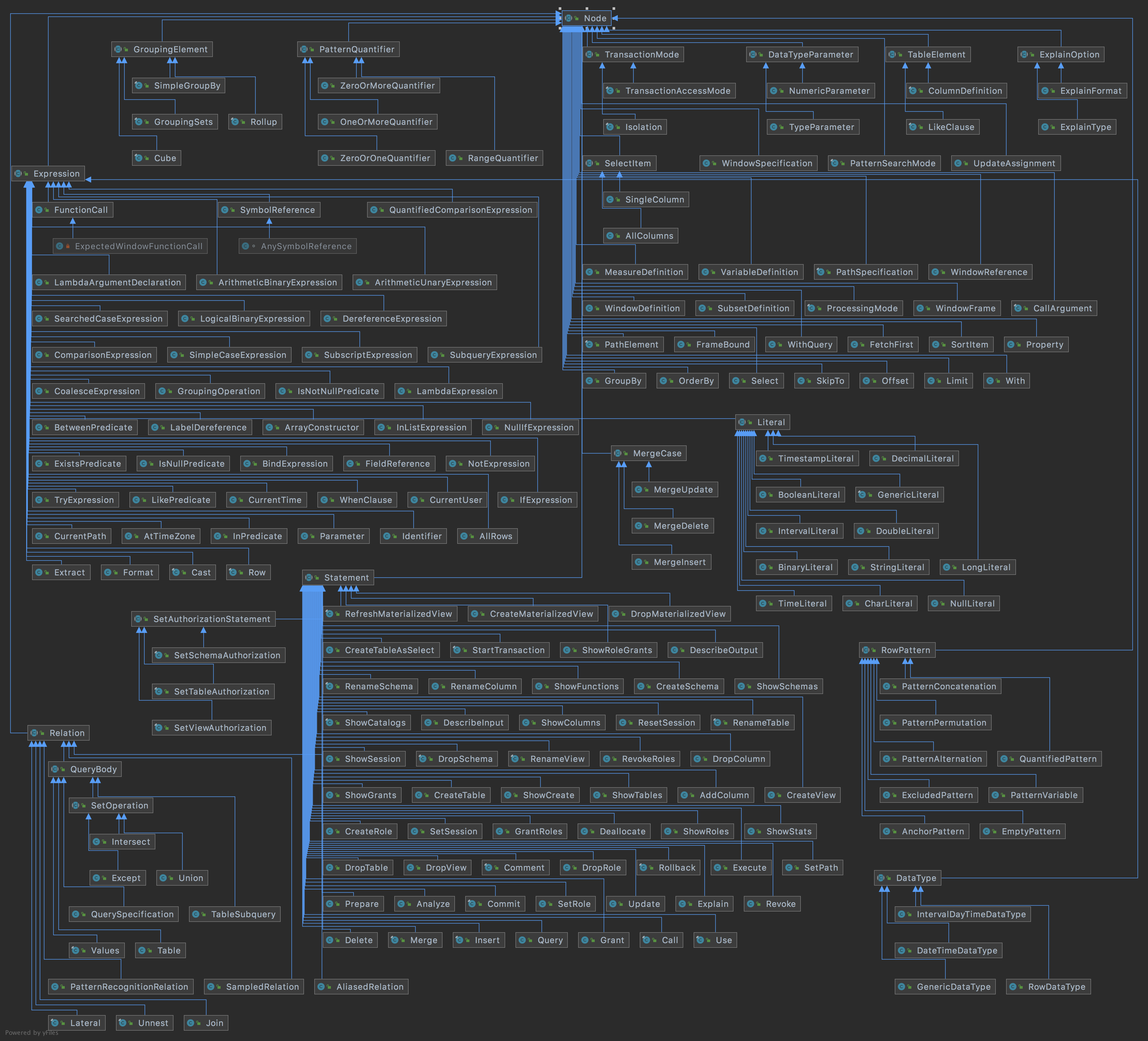
- explainOption 标识explain语句的可选参数,有explainFormat和explainType两类。explainFormat标识输出结果的格式,有text和graphviz两种类型。explainType标识explain语句的类型,有logical和distributed两类,分别标识生成逻辑执行计划与生成分布式执行计划。(上图右上角)
- expression 标识sql语句中出现的表达式。(左上,大块)
- framebound 用于窗口函数中滑动窗口的可选参数。
- relation 是一个抽象类,标识多个节点之间的关系,如join、union等。
- select 标识查询语句中的select部分。
- selectitem 标识select语句中的列类型,有allcolumns和singlecolumns两种类型。
- sortitem 标识排序的某一列及其类型。
- statement 表示presto能使用的sql类型的sql语句。(中下,大块)
- tableElement 用于表示建表语句描述表的每一列,包括列名与类型。
- window 表示一个窗口函数。
- windowFrame 表示窗口函数中欢动窗口的可选参数。
- with 表示一个查询中所有的with语句,主要元素有recursive、querys。
- withquery 表示一个with语句,主要元素有name、query、columnNames。
相比19/20年时,Trino中又多了很多,比如statement 增加了物化视图相关的类/接口
metadata API
metadata API即是matadata接口,其提供了对源数据进行各种操作的接口,列如列出所有的数据库名、表名等。这些接口在对sql进行语义分宜以及某些ddl操作(如create table)的执行过程中会用到。
metadata api将不同Connector对其元数据的各种操作抽象成统一的接口,使得在使用这些接口时无需考虑具体的底层connector实现。
metadata api除了提供对元数据操作的接口,还提供了一些通用的与connector无关的方法,例如列出presto支持的自定义函数等。
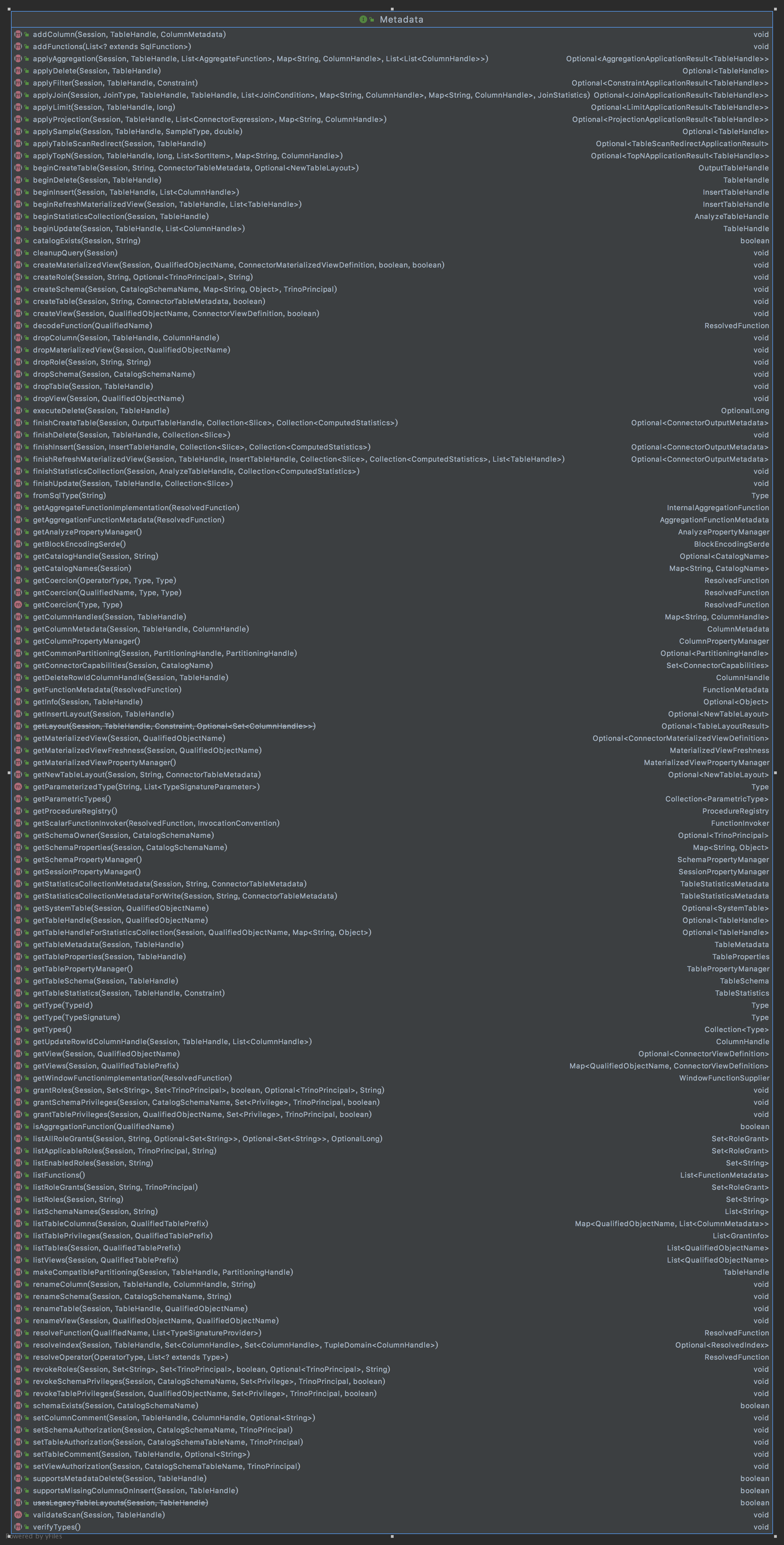
Metadata接口唯一的实现类是MeatadataManager,该类中关于元数据操作的接口的实现使用了ConnectorMetadata接口。ConnectorMetadata接口只包含MetadataAPI中元数据操作的接口(public 方法中 除了Types系列方法、Functions系列方法和属性Properties的get方法,其余几乎都是和ConnectorMetadata相关连。
获取ConnectorMetadata 的方式,是先找到CatalogName(也就是之前的ConnectorId),然后通过catalogMetadata.getMetadataFor(connectorId);得到ConnectorMetadata ,下面copy了一个方法的实现:
1 |
|
ConnectorMetadata 是开发Connector 必须要了解的,它的实现类在plugins下各个connector中实现:
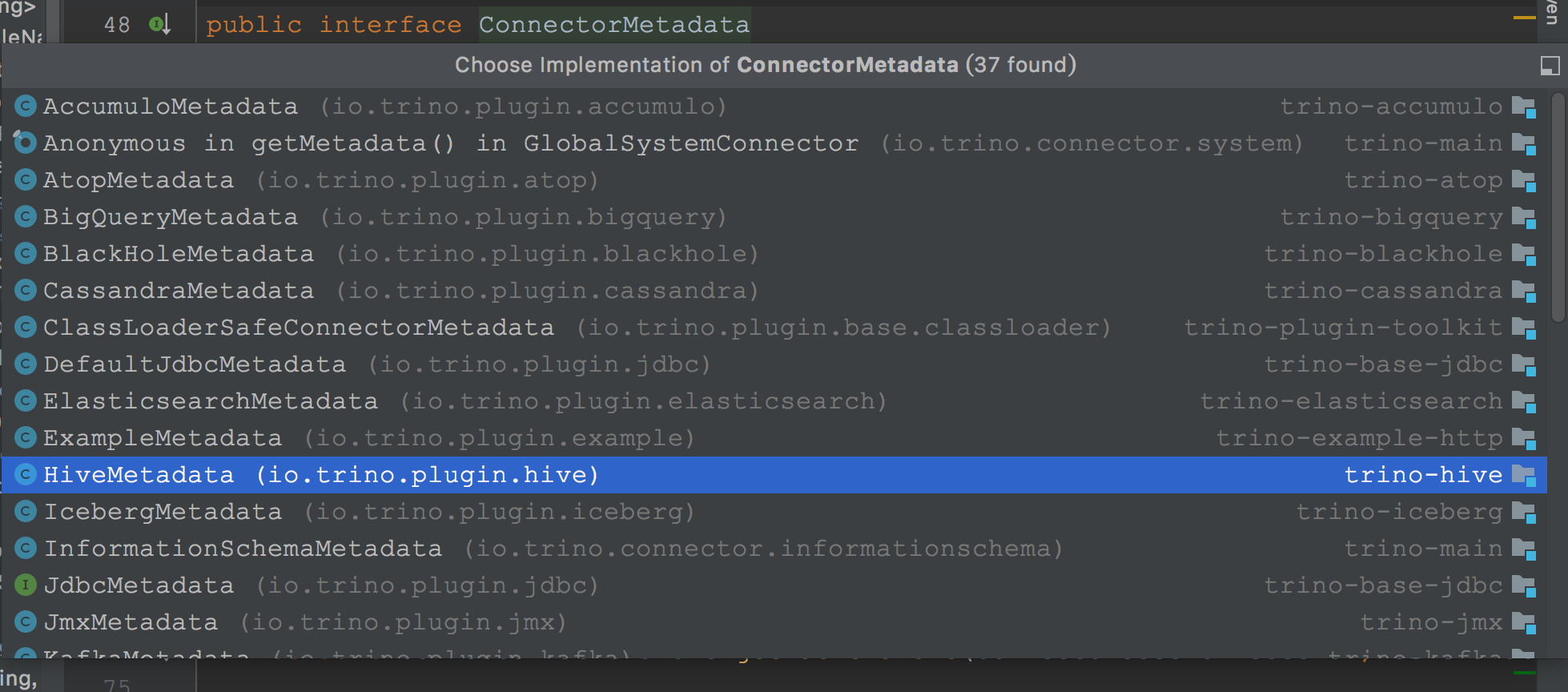

但并不是说开发connector,就必须要实现全部的方法,需要根据connector需要支持的能力复写对应的方法即可。比如不支持删除表,就可以不实现dropTable()方法,在ConnectorMetadata 接口中会抛出异常,如果提交了删除表的sql,那么在cli 或者sql异常中提示该操作不支持:
1 | /** |
在trino 的插件包中,有一个 example 示例,可以参照学习
词法与语法分析
Presto词法与语法分析的入口在SQLQueryManager 的createQuery中
语法规则
presto使用ANTLR4编写sql语法,语法规则的定义在presto-parse项目的sqlbase.g4文件中,通过ANTLR4查看该文件的语法图。
词法分析
SQLParse的createStatement方法调用其内部方法invokeParser。
语法分析
presto使用visitor模式对sql语句进行语法分析。
获取查询执行引擎
queryexecution表示一次查询执行,用于启动、停止与管理一个查询,以及统计这个查询的相关信息。
获取queryExecutionFactory
根据statement类型获取相对应的QueryExecutionFactory。QueryExecutionFactory是一个借口,其实现类有DataDefinitionExecutionFactory以及SqlQueryExecutionFactory。 executionFactories则是一个Map,存储了不同的Statement类型与QueryExecutionFactory实现类的对应关系,该map的初始化实在CoordinatorModule中进行的,对应关系如表:
create table 、rename table 等ddl操作的sql语句对应了DataDefinitionExecutionFactory,而非ddl操作的sql语句。例如select、insert等对应了SqlQueryExecutionFactory。
创建QueryExecution
当以上的词法与语法分析出错,照着找不到statement实现类与QueryExecutionFactory实现类的对应关系时,将创建一个FailedQueryExecution,冰封装错误信息,最后返回给用户。
调用之前获取的QueryExecutionFactory的createQueryExecution方法,获取对应的QueryExecution。DataDefinitionExecutionFactory创建的是DataDefinitionExecution,而
SqlQueryExecutionFactory创建的是SqlQueryExecution。
在DataDefinitionExecutionFactory创建DataDefinitionExecution时,根据statement类型将对应的DataDefinitionExecutionTask实现类与DataDefinitionExecution绑定。
启动QueryExecution
获取QueryExecution之后,SqlQueryQueueManager方法将QueryExecution与配置的查询队列规则进行匹配,如匹配成功且队列未满,则将QueryExecution加入匹配队列。查询队列按照 FIFO规则调度查询。最后启动QueryExecution。 DataDefinitionExecution启动直接调用其绑定的DataDefinitionTask实现类的execute方法即可。以dropTable为例,由于DropTable与dropTableTask绑定,会执行DropTableTask 的execute方法。 SqlQueryExecution启动比较复杂,需要执行查询计划、优化查询计划、分阶段执行查询计划。
语义分析
由于DataDefinitionExecution的执行直接调用DataDefinitionTask实现类的execute方法,并未经过执行计划生成的步骤,故以下的内容只针对SqlQueryExecutionFactory。
statement分析
statementAnalyzer是对statement进行予以分析的类,针对不同的statement实现类进行语义分析。
relation分析
TupleAnalyzer类是对Query中的Relation进行分析的类。
表达式分析
ExpressionAnalyzer类对sql语句中的表达式进行分析,主要功能如下:
获取表达式的类型
获取需要进行类型转换的表达式及其转换的目的类型。
获取表达式中存在的函数信息。
获取表达式中所有合法的列名及对应列的编号。
获取表达式中In语句中的子查询。
执行计划生成
LogicalPlanner类会根据以上针对SQL语句分析所得的结果,生成逻辑执行计划。
执行计划节点
在讲解执行计划生成之前,首先介绍一下执行计划树中的节点类型。
- AggregationNode 是用于聚合操作的节点,聚合的类型有Final、Partial、Single三种,分别表示最终聚合、局部聚合和单点聚合,其中执行计划在进行优化之前,聚合的类型都是单点聚合,在执行计划优化器中会对其进行拆分成局部聚合和最终聚合。
- DeleteNode 是用于Delete操作的节点。
- DistinctLimitNode 是用于处理以下类型的sql语句的节点。
- ExchangeNode 是用于在执行计划中不同stage之间交换数据的节点,出现在逻辑执行计划中。
- FilterNode 是用国语进行过滤操作的节点
- IndexJoinNode 是用于对Index Join操作的节点。
- IndexSorceNode 是与Index join配合使用的执行数据源读取操作的节点。
- JoinNode 是执行Join操作的节点
- LimitNode 是执行limit操作的节点
- MarkDistinctNode 是用于处理一下outputNode、projectNode的sql语句的节点。
- OutputNode 输出最终结果的节点
- project 用于进行列映射的节点,用于将ProjectNode下层节点输出的列映射到Project上层节点输入的列。
- RemoteSourceNode 类似于ExchangeNode,用于分布式执行计划中不同的stage之间交换数据,出现在分布式执行计划中
- RowNumberNode 用于处理窗口函数row_number
- SampleNode 用于处理抽样函数
- SemiJoinnode 用于处理执行计划生成过程中产生的SemiJoin。
- SortNode 用于排序操作。
- TableCommitNode 用于对create table as select语句、insert语句、delete语句的操作执行commit。
- TableScanNode 用于读取表的数据。
- TableWriterNode 用于向目的的表写入数据。
- TopNNode 用于取数据排序后的前N条结果,使用效率更高的TopN算法,而不是对所有数据进行全局派去在取前N条,TopN题与算法不在具体详述。
- TopNRowNumberNode 用于处理窗口函数row_number中排序前N条记录,使用效率更高的TopN算法。
- UnionNode 用于处理Union操作
- UnnestNode 用于处理Unnest操作
- ValuesNode 用于处理Values语句。
- WindowNode 用于处理窗口函数。
sql执行计划
LogicalPlanner负责整个sql语句执行计划的生成,根据sql语句的类型生成不同的执行计划,然后针对生成的执行计划,分别使用已注册的执行计划优化器进行优化。
- TableWriter Plan
crate table as select 语句和insert语句都会生成tablewriterplan,其所生成的执行计划树如下。
其中queryplan是指create table as select语句或insert语句后面的查询语句生成的执行计划树,在tablewriternode和outputnode之间添加tablecommitnode可以防止数据写入失败导致的中间状态, 但确保数据写入成功之后再进行commit操作。
- Deleteplan
Delete语句生成DeletePlan,其执行进化树结果如图。
- queryplan
所有relation类型的sql语句都会生成queryplan,由下一节中的relationPlanner分析并生成查询执行计划。