
Presto执行计划-生成计划
阅读源码时梳理逻辑用,无阅读价值
在创建 dispatchQuery 的最后,返回了一个LocalDispatchQuery,其构造函数最后一个参数调用了 SqlQueryExecution 的start()方法
1 | return new LocalDispatchQuery( |
1 | // analyze query |
analyzer.analyze(statement)方法,主要是构造了一个StatementAnalyzer对传入的statement 进行分析,将分析结果存入Analysis中返回
Statement语义分析
StatementAnalyzer 是对statement 进行语义分析的类,针对不同的statement实现类进行不同的语义分析:
1 | public Analysis analyze(Statement statement) |
上述该方法主要先对statement进行rewrite,对非标准命令转换为sql指令,然后构造了一个StatementAnalyzer对传入的statement进行分析,将结果存储在Analysis中返回
提前重写statement类型包括:
- 包括show xxx系列: 比如show catalogs/show schemas/show tables/show functions/show columns/show session(当前连接会话的配置)
- SHOW STATS FOR table|query: 查看表格/查询的统计信息,例如:SHOW STATS FOR ( SELECT * FROM table [ WHERE condition ] )
- explain sql : 查看sql 执行计划,包含两种类型,Logical逻辑计划 和 Distributed分布式计划
- DescribeInputRewrite和DescribeOutputRewrite ,desc 命令?没看出来干嘛的….
StatementAnalyzer 是对Statment进行语义分析的类,针对不同的Statement实现类进行语义分析,具体实现在内部类Visitor,该类的类视图如下所示:
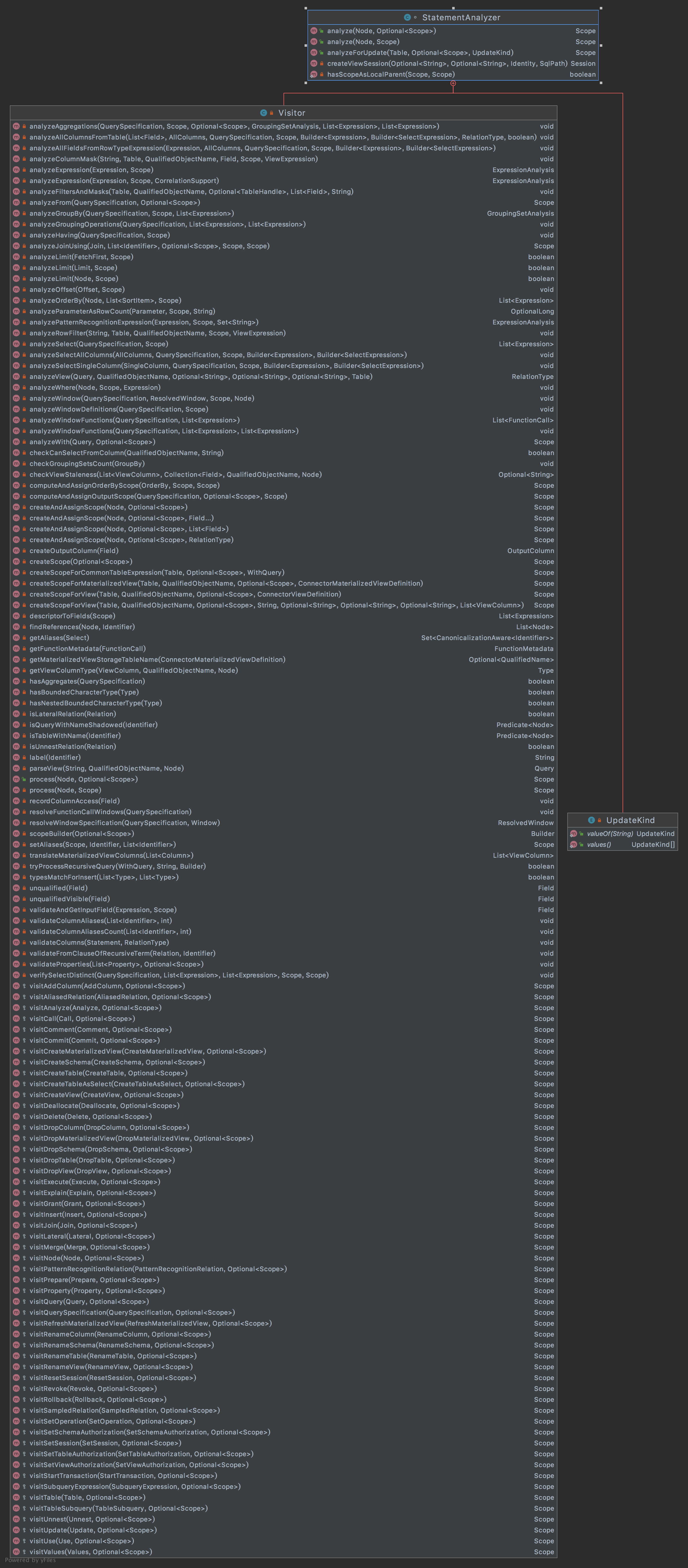
观察 visitXxx方法,返回的是Scope,Scope主要包括:
1 | public class Scope |
可以看出,Scope 包含了一系列的Field,一个field 表示对一个字段的描述,每个field 包含源表、源列名、别名、字段名、字段类型、是否隐藏、是否有别名
对于select 语句(包括StatementRewrite处理过的),返回的scope 包含取到的每一列,每一个field 表示一列;
对于insert语句、delete和create Table as select 语句,返回的scope 只有一列,表示语句执行所操作的行数
StatementAnalyzer的Visitor的visitXxx方法针对不同的statement实现类做了处理,以下针对不同的statement分别进行拆解:
1.元信息相关的命令分析
在Statement rewrittenStatement = StatementRewrite.rewrite()环节,已经将所有的 Show Tables、 sho w schemas、show catalogs、 show columns、show functions、show partitions、show session转换为了标准的select,其中用到的库是 information_schema
presto 在启动时为每一个Catalog都建立了一个information_schema库,共6张表,
__internal_functions__:存储了Presto内部注册的所有函数 (trino356 中已经没有了)__internal_partitions: 存储了当前Catalog下所有分区表的分区信息 (trino356 中已经没有了)columns: 存储了当亲啊Catalog下所有表的列信息schemata:存储了当前Catalog下所有的库信息tables: 存储了当前Catalog下所有的表信息views: 存储了当前Catalog下所有的视图信息
trino356 版本中多了5张表,,但很多Connector 并不支持:
applicable_roles: 适用的角色enabled_roles:启用的角色role_authorization_descriptors: 角色 授权roles:角色列表table_privileges: 表权限
use 命令
use命令是用来切换 catalog 和schema的,只在Cli 连接时才有用,JDBC等其他方式不支持该语法。比如 use hive.default 。在Visitor 中是 visitUse()方法
2 Create View
1 |
|
并不是所有的数据源都支持Create View 操作
3 Insert
1 |
|
Query
1 |
|
1 |
|
Plan plan = logicalPlanner.plan(analysis); 一直跟进去,最终的执行计划生成见下面的代码:
1 | public Plan plan(Analysis analysis, Stage stage, boolean collectPlanStatistics) |