大数据分析的下一代架构–IOTA架构设计实践
基于 易观CTO 郭炜 文章 Lambda架构已死,去ETL化的IOTA才是未来 和 易观方舟IOTA架构实践整理而成
IOTA架构提出背景
在过去,Lambda数据架构成为每一个公司大数据平台必备的架构,它解决了一个公司大数据批量离线处理和实时数据处理的需求。一个典型的Lambda架构如下:
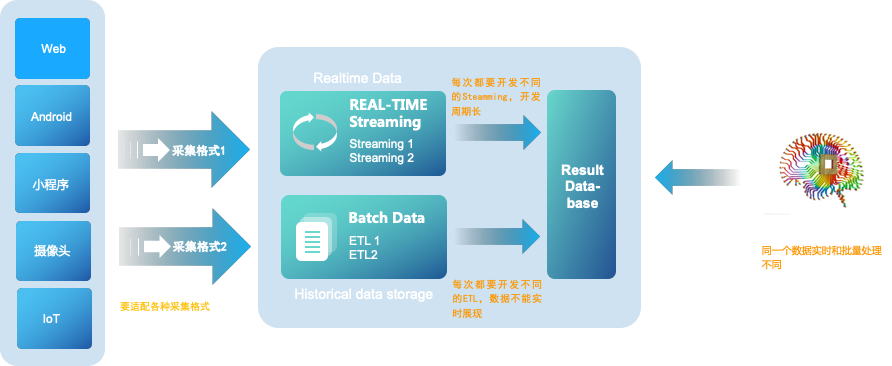
数据从底层的数据源开始,经过各种各样的格式进入大数据平台,在大数据平台中经过Kafka、Flume等数据组件进行收集,然后分成两条线进行计算。一条线是进入流式计算平台(例如 Storm、Flink或者Spark Streaming),去计算实时的一些指标;另一条线进入批量数据处理离线计算平台(例如Mapreduce、Hive,Spark SQL),去计算T+1的相关业务指标,这些指标需要隔日才能看见。
Lambda架构经历多年的发展,其优点是稳定,对于实时计算部分的计算成本可控,批量处理可以用晚上的时间来整体批量计算,这样把实时计算和离线计算高峰分开,这种架构支撑了数据行业的早期发展,但是它也有一些致命缺点,并在大数据3.0时代越来越不适应数据分析业务的需求。缺点如下:
实时与批量计算结果不一致引起的数据口径问题:因为批量和实时计算走的是两个计算框架和计算程序,算出的结果往往不同,经常看到一个数字当天看是一个数据,第二天看昨天的数据反而发生了变化。
批量计算在计算窗口内无法完成:在IOT时代,数据量级越来越大,经常发现夜间只有4、5个小时的时间窗口,已经无法完成白天20多个小时累计的数据,保证早上上班前准时出数据已成为每个大数据团队头疼的问题。
数据源变化都要重新开发,开发周期长:每次数据源的格式变化,业务的逻辑变化都需要针对ETL和Streaming做开发修改,整体开发周期很长,业务反应不够迅速。
服务器存储大:数据仓库的典型设计,会产生大量的中间结果表,造成数据急速膨胀,加大服务器存储压力
IOTA架构
而在IOT大潮下,智能手机、PC、智能硬件设备的计算能力越来越强,而业务需求要求数据实时响应需求能力也越来越强,过去传统的中心化、非实时化数据处理的思路已经不适应现在的大数据分析需求,我提出新一代的大数据IOTA架构来解决上述问题,整体思路是设定标准数据模型,通过边缘计算技术把所有的计算过程分散在数据产生、计算和查询过程当中,以统一的数据模型贯穿始终,从而提高整体的预算效率,同时满足即时计算的需要,可以使用各种Ad-hoc Query来查询底层数据:
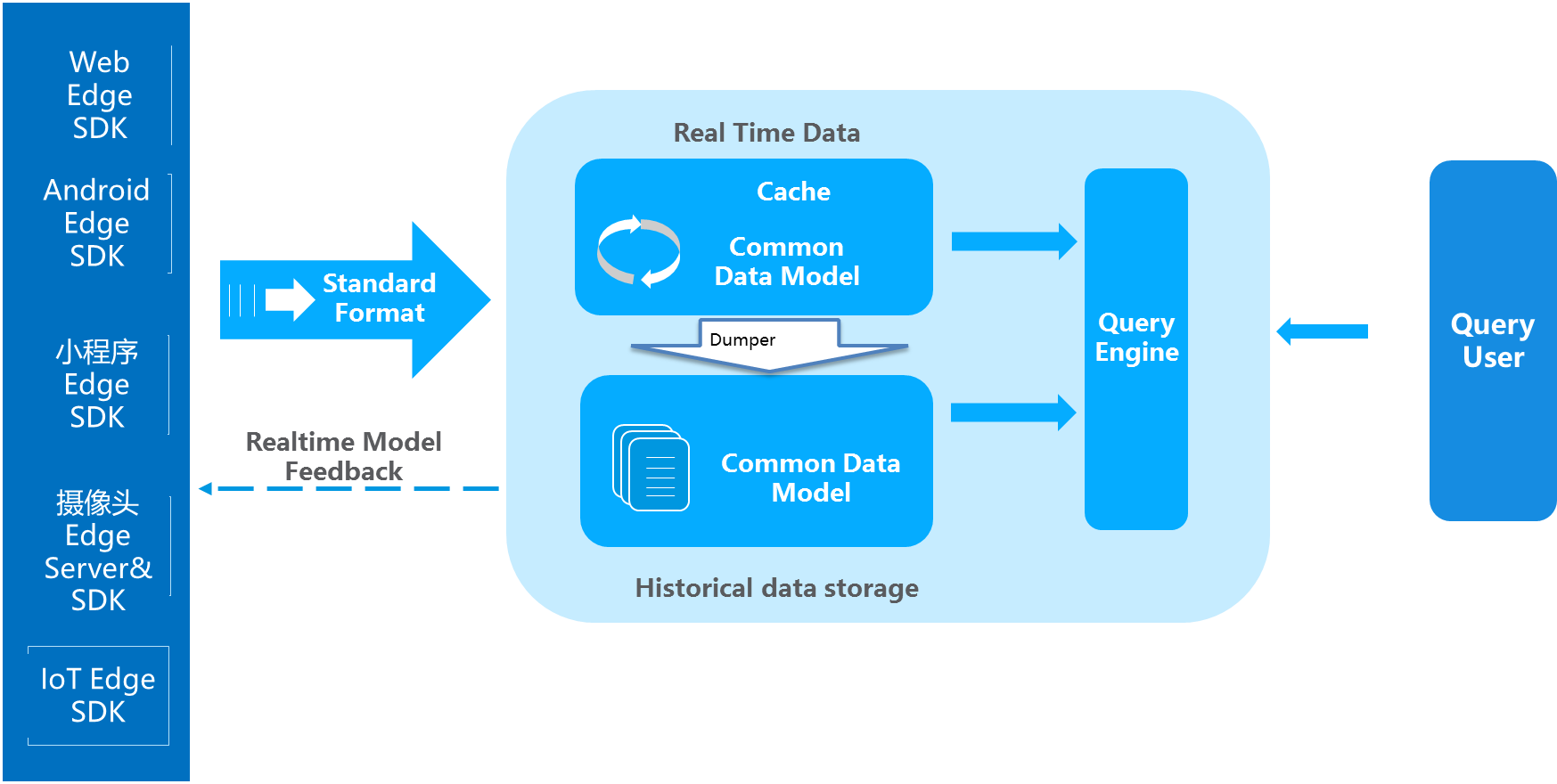
IOTA整体技术结构分为几部分:
Common Data Model:贯穿整体业务始终的数据模型,这个模型是整个业务的核心,要保持SDK、cache、历史数据、查询引擎保持一致。对于用户数据分析来讲可以定义为“主-谓-宾”或者“对象-事件”这样的抽象模型来满足各种各样的查询。以大家熟悉的APP用户模型为例,用“主-谓-宾”模型描述就是
X用户 – 事件1 – A页面(2018/4/11 20:00)。当然,根据业务需求的不同,也可以使用“产品-事件”、“地点-时间”模型等等。模型本身也可以根据协议(例如 protobuf)来实现SDK端定义,中央存储的方式。此处核心是,从SDK到存储到处理是统一的一个Common Data Model。Edge SDKs & Edge Servers:这是数据的采集端,不仅仅是过去的简单的SDK,在复杂的计算情况下,会赋予SDK更复杂的计算,在设备端就转化为形成统一的数据模型来进行传送。例如对于智能Wi-Fi采集的数据,从AC端就变为
X用户的MAC 地址-出现- A楼层(2018/4/11 18:00)这种主-谓-宾结构,对于摄像头会通过Edge AI Server,转化成为X的Face特征- 进入- A火车站(2018/4/11 20:00)。也可以是上面提到的简单的APP或者页面级别的X用户 – 事件1 – A页面(2018/4/11 20:00),对于APP和H5页面来讲,没有计算工作量,只要求埋点格式即可。Real Time Data:实时数据缓存区,这部分是为了达到实时计算的目的,海量数据接收不可能海量实时入历史数据库,那样会出现建立索引延迟、历史数据碎片文件等问题。因此,有一个实时数据缓存区来存储最近几分钟或者几秒钟的数据。这块可以使用Kudu或者Hbase等组件来实现。这部分数据会通过Dumper来合并到历史数据当中。此处的数据模型和SDK端数据模型是保持一致的,都是Common Data Model,例如“主-谓-宾”模型。
Historical Data:历史数据沉浸区,这部分是保存了大量的历史数据,为了实现Ad-hoc查询,将自动建立相关索引提高整体历史数据查询效率,从而实现秒级复杂查询百亿条数据的反馈。例如可以使用HDFS存储历史数据,此处的数据模型依然SDK端数据模型是保持一致的Common Data Model。
Dumper:Dumper的主要工作就是把最近几秒或者几分钟的实时数据,根据汇聚规则、建立索引,存储到历史存储结构当中,可以使用map reduce、C、Scala来撰写,把相关的数据从Realtime Data区写入Historical Data区。
Query Engine:查询引擎,提供统一的对外查询接口和协议(例如SQL JDBC),把Realtime Data和Historical Data合并到一起查询,从而实现对于数据实时的Ad-hoc查询。例如常见的计算引擎可以使用presto、impala、clickhouse等。
Realtime model feedback:通过Edge computing技术,在边缘端有更多的交互可以做,可以通过在Realtime Data去设定规则来对Edge SDK端进行控制,例如,数据上传的频次降低、语音控制的迅速反馈,某些条件和规则的触发等等。简单的事件处理,将通过本地的IOT端完成,例如,嫌疑犯的识别现在已经有很多摄像头本身带有此功能。
IOTA 架构实例-方舟
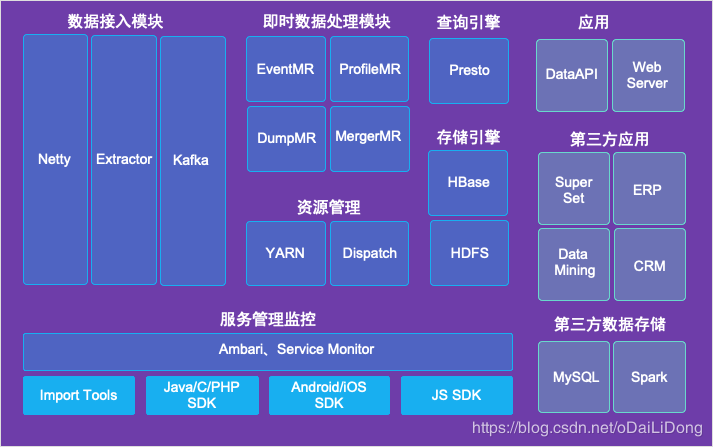
IOTA 架构特点
IOTA大数据架构,主要有如下几个特点:
去ETL化:ETL和相关开发一直是大数据处理的痛点,IOTA架构通过Common Data Model的设计,专注在某一个具体领域的数据计算,从而可以从SDK端开始计算,中央端只做采集、建立索引和查询,提高整体数据分析的效率。
Ad-hoc即时查询:鉴于整体的计算流程机制,在手机端、智能IOT事件发生之时,就可以直接传送到云端进入real time data区,可以被前端的Query Engine来查询。此时用户可以使用各种各样的查询,直接查到前几秒发生的事件,而不用在等待ETL或者Streaming的数据研发和处理。
边缘计算(Edge-Computing):将过去统一到中央进行整体计算,分散到数据产生、存储和查询端,数据产生既符合Common Data Model。同时,也给与Realtime model feedback,让客户端传送数据的同时马上进行反馈,而不需要所有事件都要到中央端处理之后再进行下发。
IOTA架构 — 数据模型 Common Data Model
Event-User 模型之 事件(event)
主要是描述用户做了什么事情,记录用户触发的行为,例如注册、登录、支付事件等等,用以记录用户在何时通过何种方式发生了何种行为
Event 核心是何人 (xwho) 、何时 (xwhen) 、何地 (xwhere) 、通过何种方式 (xcontext) 、发生了何种行为 (xwhat) 五要素,比如 xiaozhou 在2018-01-31 07:02:48 通过Chrome 浏览器打开了易观方舟网站,这就会触发一个事件,上报如下格式的数据:
1 | [ |
Event-User 模型之 用户(profile)
用以记录用户属性相关的信息,来描述用户,进一步进行画像等。
1 | [ |
方舟的事件模型中,数据上报时会有用户这个实体,使用 who 来进行标识,在登录前匿名阶段,who 中会记录一个 匿名 ID ,登录后会记录一个注册 ID。
1.1 匿名 ID
匿名 ID 用来在用户主体未登录应用之前标识,当用户打开集成有方舟 SDK 的应用时,SDK 会给其分配一个 UUID 来做为匿名 ID 。
当然,方舟也提供了给用户主体设置匿名 ID 的方式,比如可以使用设备 ID ( iOS 的 IDFA/IDFV,Web 的 Cookie 等)。
1.2 注册 ID
通常是业务数据库里的主键或其它唯一标识,注册 ID 是更加精确的用户 ID,但很多应用不会用注册 ID,或者用户使用一些功能时是在未登录的状态下进行的,此时,就不会有注册 ID。
另外,在方舟系统中,我们以为用户主体来进行分析,这个用户主体可能是一个人,一个帐号,也可能是一个家电,一辆汽车。具体以什么做为用户主体,要根据用户实际的业务场景来决定。
1.3 distinct_id
即使有了who( 注册 ID / 匿名 ID),实际使用中也会存在注册用户匿名访问等情况,所以需要一个唯一标识将用户行为贯穿起来,distinct_id 就是在who 的基础上根据一些规则生成的唯一 ID。
更多模型相关
https://ark.analysys.cn/docs/integration-data-model.html
IOTA架构 — 数据流转过程
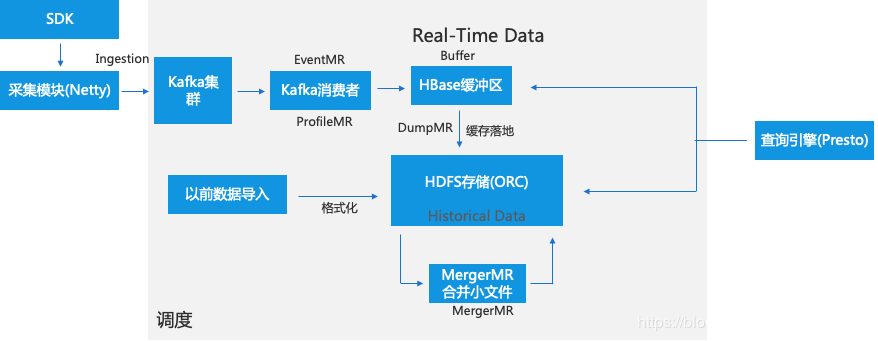
分Event-Profile 数据流

IOTA架构 — 数据采集(Ingestion)

数据采集要注意:
传输加密
策略控制
- 服务器可以随时更改发发送策略,比如发送频率调整,重试频率
- 发送策略优先级: 服务器策略>debug>用户设置>启动、间隔策略
- 服务器约束示例

IOTA架构 — 数据缓冲区(Real-Time Data)
Real-Time Data区是数据缓冲区,当从Kafka消费完数据首先落入Buffer区,这样设计主要是因为目前主流存储格式都不支持实时追加(Parquet、ORC)。Buffer区一般采用HBase、Kudu等高性能存储,考虑到成熟度、可控、社区等因素,我们采用HBase。
HBase的特点:
- 主键查询速度快
- Scan性能慢
如何解决Scan性能:— In-memory
- Snappy压缩
- 动态列簇
- 只存一定量的数据
- Rowkey hash化
- hfile数据转换成OrcFile
IOTA架构 — 历史存储区(Historical data storage)
当HBase里的数据量达到百万规模时,调度会启动DumpMR(Spark、MR任务)会将HBase数据flush到HDFS中去,因为还要支持数据的实时查询,我们采用R/W表切换方案,即一直写入一张表直到阈值,就写入新表,老表开始转为ORC格式。
HDFS高效存储:
- 按天分区
- 基于用户ID,事件时间排序
- 冷热分层
- Orc存储
- BloomFilter(无
- 稀疏索引(无
- Snappy压缩
- 小文件问题:不按事件分区、MergerMR定时合并小文件
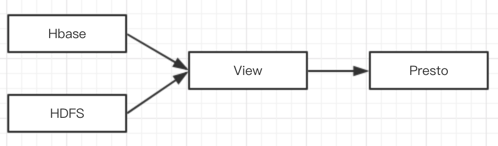
IOTA架构 — 即时查询引擎(Query Engine)
因为需支持从历史到最近一条数据的即时查询,查询引擎需要同时查HBase缓冲区里和历史存储区的数据,采用View视图的方式进行查询。
方舟的Query Engine基于Presto进行二次开发
HBase-Connector定制开发、优化
通过视图View建立热数据与历史数据的联合计算
Session,漏斗,留存,智能路径等模型的算法实现
IOTA架构 — 优化策略/方向

1、添加布隆过滤器,TPC-DS有50%-80%性能提升
2、全局 + 局部字典,尽量整型,避免过长字符串,数倍性能提升
如:事件名称使用id,查询速度提升近1倍
3、数据缓存Alluxio使用,2~5倍性能提升
4、SQL优化,耗时sql优化非常重要
5、Unsafe调用。Presto里开源Slice的使用