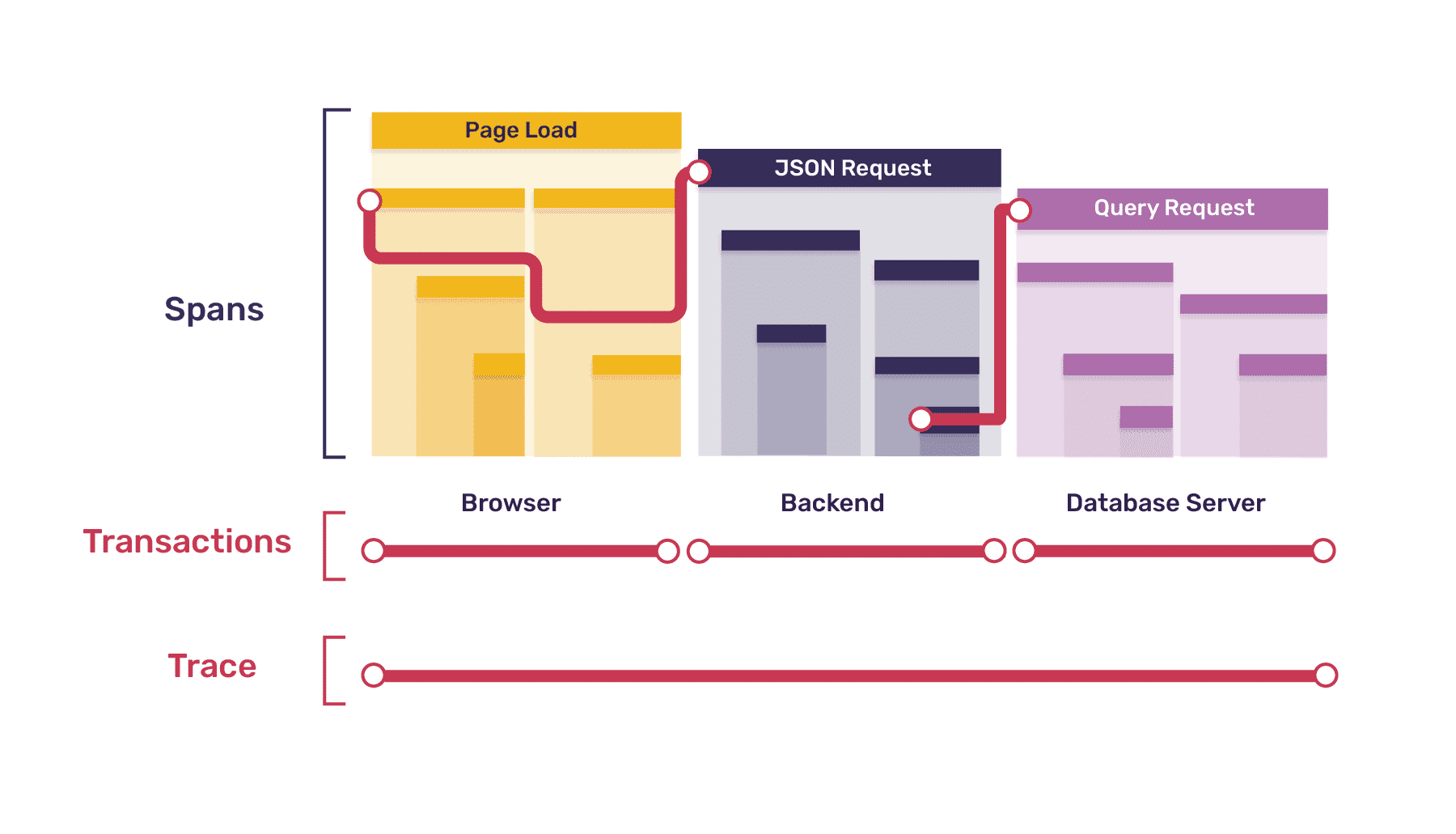


分布式 Trace 数据模型
distributed-tracing 数据模型
通过跟踪从前端到后端的交互,通过trace数据,可以扩展现有的错误数据,跟踪软件的性能,测量吞吐量和延迟等指标,并显示跨多个系统的错误影响:
- 出现特定错误事件或问题时发生了什么
- 哪些因素导致应用程序出现瓶颈或延迟问题
- 哪些的endpoint或操作消耗时间最多
什么是追踪?
首先,请注意Trace不是什么:Trace不是分析。尽管概要分析和跟踪的目标有相当多的重叠,虽然它们都可用于诊断应用程序中的问题,但它们在测量的内容和记录数据的方式方面有所不同。
一个Profiler可以测量任何数目的应用程序的操作的各方面的:指令执行数,正在使用的各种处理的内存量,给定的时间的函数调用需要的量,等等。生成的配置文件是这些测量值的统计汇总。
一个tracer工具,在另一方面,侧重于什么事(何时),而不是发生了多少次发生或者花了多长时间。trace的结果是在程序执行期间发生的事件日志,这些事件往往跨越多个系统。就 Sentry 的跟踪而言,总是——包括时间戳,允许计算持续时间,但测量性能并不是它们的唯一目的。它们还可以显示互连系统交互的方式,以及一个系统中的问题可能导致另一个系统出现问题的方式。
(备注:除了测量性能外,还可以做故障的根因分析)


