



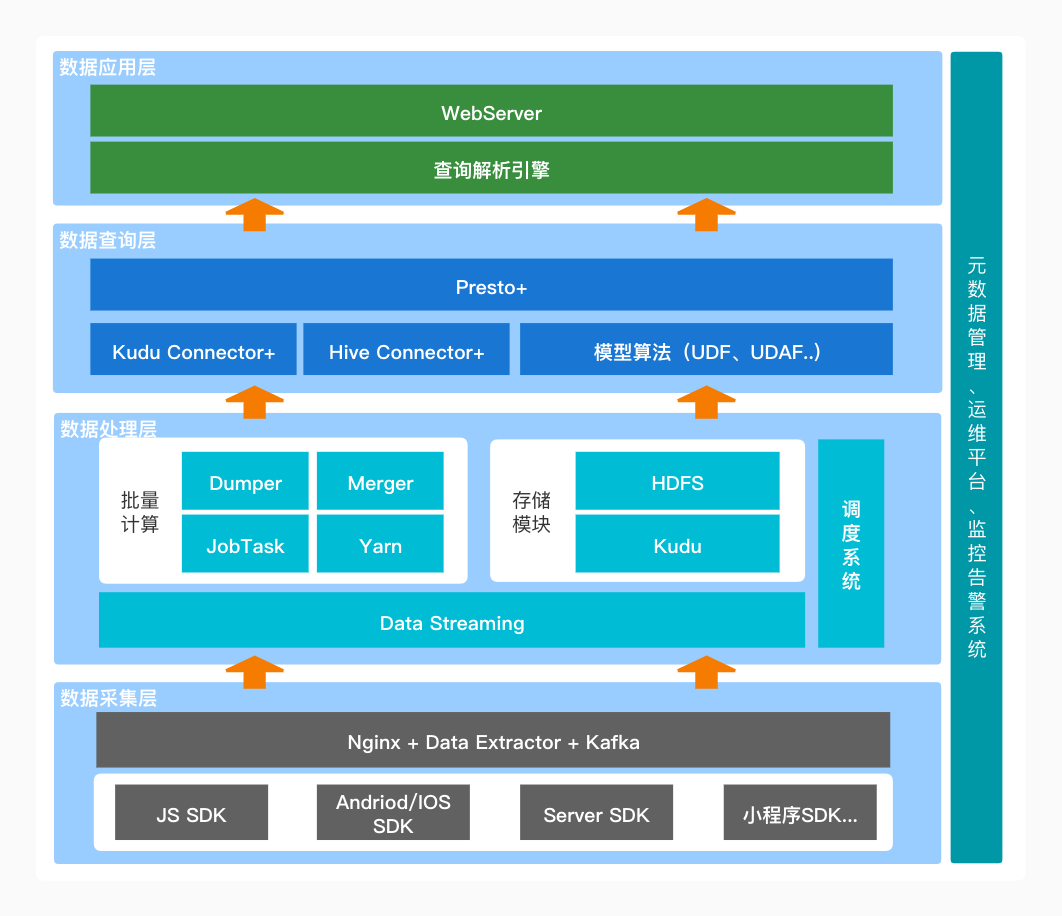




行为数据存储中的分区和分桶
存储引擎一般都支持分区分桶
分区的意义在于将数据分散到多个子目录中,在执行查询时,可以只选择查询某些子目录中的数据来加快查询效率。
分桶的意义实际和分区一样,只是并非所有的数据都可以形成合理的分区,而分桶可以弥补分区这个缺陷,将数据集分解为若干部分
分区可以做多级分区,分区的个数可以指定,也可以由程序自动生成, 分区是可以动态增长的
分桶的个数是一经决定,就不能更改,所以如果要改变桶数,要重新插入分桶数据
行为数据本质是时序数据,所以分割的关键要素第一肯定是 时间,第二个分割的关键要素就是 事件


