
Kudu 删除表range分区
https://kudu.apache.org/docs/command_line_tools_reference.html#table-drop_range_partition
注意事项
- 一次只能删一个分区
- 分区条件必须前后精准匹配
- 可以通过
kudu table describe查看表信息(包括分区信息):
1 | # 查看表信息,包括列、分区信息 |

https://kudu.apache.org/docs/command_line_tools_reference.html#table-drop_range_partition
注意事项
kudu table describe查看表信息(包括分区信息):1 | # 查看表信息,包括列、分区信息 |
https://kudu.apache.org/docs/command_line_tools_reference.html#table-copy
注意事项:
write_type 参数有3种:
阅读源码时梳理逻辑用,无阅读价值
queryexecution表示一次查询执行,用于启动、停止与管理一个查询,以及统计这个查询的相关信息。
在 经过Antlr 4语法解析起进行语法分析后,最终生成了一个Node,然后转成Statement,然后再包装成PreparedQuery
再看后续代码,在 dispatchQueryFactory.createDispatchQuery()方法中对不同类型的Statement 进行分发处理,其中对应的类为:QueryExecutionFactory
1 | preparedQuery = queryPreparer.prepareQuery(session, query); |

阅读源码时梳理逻辑用,无阅读价值
在创建 dispatchQuery 的最后,返回了一个LocalDispatchQuery,其构造函数最后一个参数调用了 SqlQueryExecution 的start()方法

阅读源码时梳理逻辑用,无阅读价值
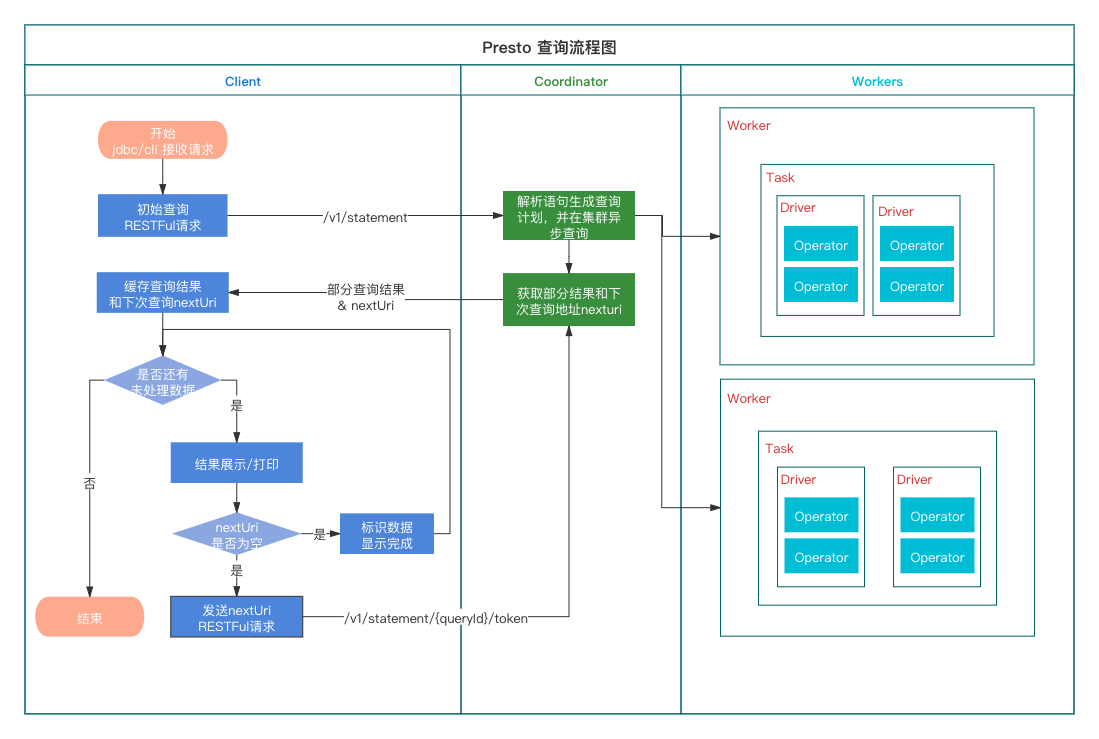
如果要跟可以从上一节提交查询过程中client 发送给coordinator 的提交查询API (/v1/statement)开始跟
client初始提交query后,coordinator 创建了一个Query,然后组装nextUri 后直接response了,这时候 query 尚未排队,只有当client 来请求query状态了(/v1/statement/queued/{queryId}/{slug}/{token}),这时才将其加入到调度队列中

生成查询计划 分为 语法分析、词法分析、语义分析、执行计划生成、执行计划优化、执行计划分阶段执行。

经过词法和语法分析后,会生成抽象语法树(AST),该语法树中的每一个节点都是Node(SQL语句的一部分,例如select部分,where部分),Node是一个抽象类,其实现类如下图,特别庞大:
阅读源码时梳理逻辑用,无阅读价值
Presto/Trino 客户端对查询语句的提交分三个步骤:

cli提交查询的入口在:client 目录下的trino-cli 工程中,入口类io.trino.cli.Trino
每一次ad-hoc查询,均是会占用有限的计算资源,而OLAP 系统在现有技术下,并不能支撑很高的查询并发,为了有效改善这个问题,在查询时间范围内数据未发生变化或者变化量小,有效运用缓存可以有效提高查询效率和用户体验
对SQL的查询结果进行缓存,可以在 adhoc 层 或者 api 层进行处理
判断主机/虚拟机是否支持 sse4_2 指令集:
1 | grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported“" |
由于物理主机的CPU是支持该指令集的,所以只需要修改虚拟机的主机模式

1 | service kudu-master restart |
1 | sudo -u kudu kudu cluster ksck master1,master2,master3 > ./ksck.out 2>&1 |
Update your browser to view this website correctly. Update my browser now

